从本讲开始,我们将以首次渲染为切入点,拆解 Fiber 架构下 ReactDOM.render 所触发的渲染链路,结合源码理解整个链路中所涉及的初始化、render 和 commit 等过程
# 一、ReactDOM.render 调用栈的逻辑分层
开篇先给到你一个简单的 React AppDemo:
import React from "react";
import ReactDOM from "react-dom";
function App() {
return (
<div className="App">
<div className="container">
<h1>我是标题</h1>
<p>我是第一段话</p>
<p>我是第二段话</p>
</div>
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
Demo 启动后,渲染出的界面如下图所示:

现在请你打开 Chrome 的 Performance 面板,点击下图红色圈圈所圈住的这个“记录”按钮:
然后重新访问 Demo 页面对应的本地服务地址,待页面刷新后,终止记录,便能够得到如下图右下角所示的这样一个调用栈大图:
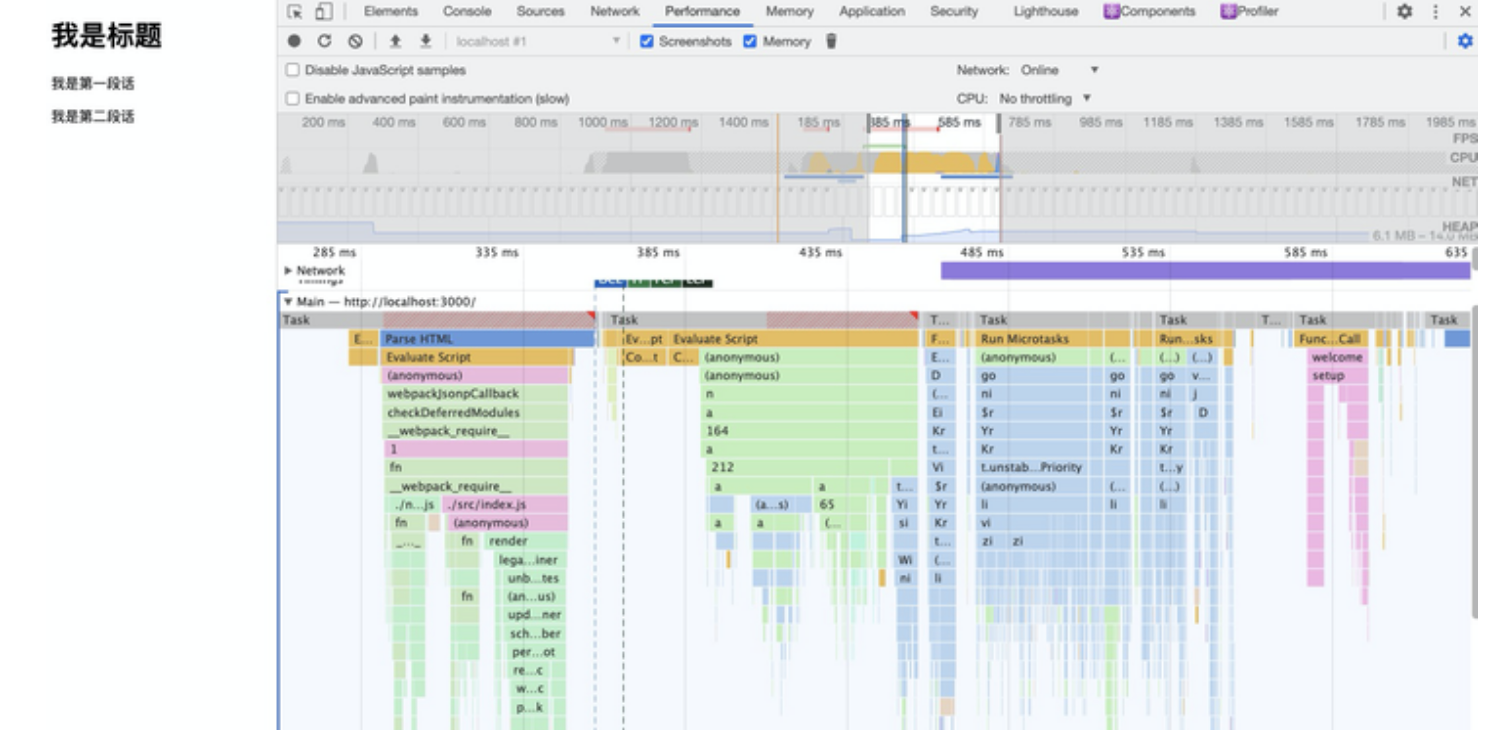
放大该图,定位“src/index.js”这个文件路径,我们就可以找到 ReactDOM.render 方法对应的调用栈,如下图所示:
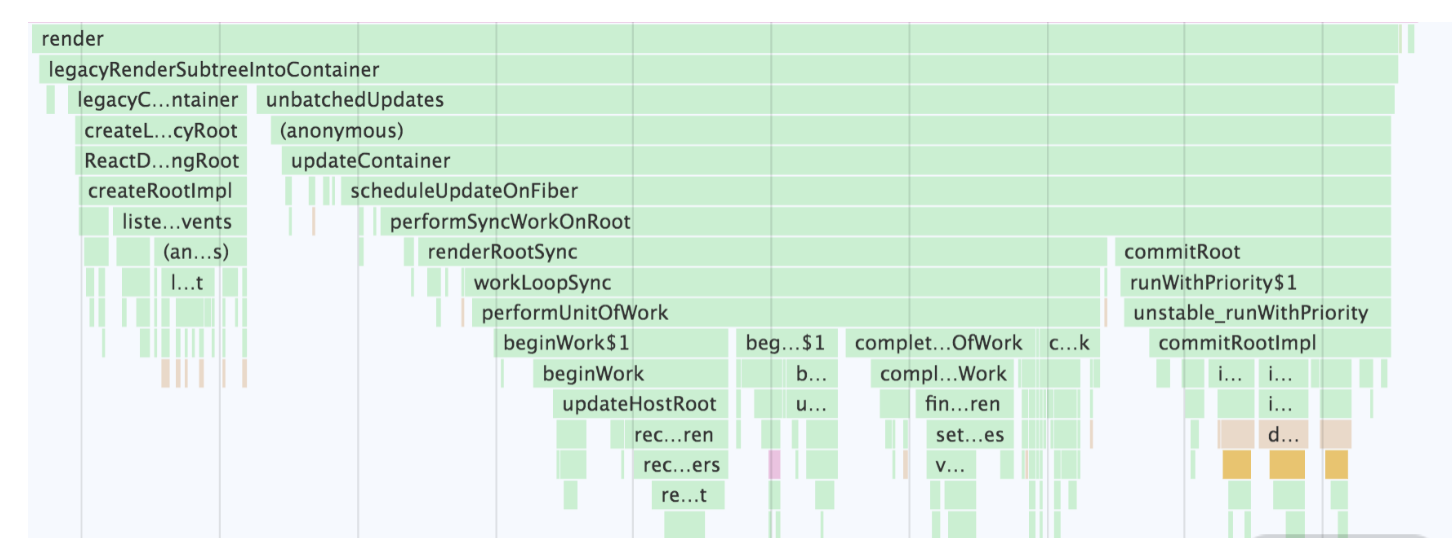
从图中你可以看到,ReactDOM.render 方法对应的调用栈非常深,中间涉及的函数量也比较大。如果这张图使你心里发虚,请先不要急于撤退——分析调用栈只是我们理解渲染链路的一个手段,我们的目的是借此提取关键逻辑,而非理解调用栈中的每一个方法。就这张图来说,你首先需要把握的,就是整个调用链路中所包含的三个阶段

图中 scheduleUpdateOnFiber 方法的作用是调度更新,在由 ReactDOM.render 发起的首屏渲染这个场景下,它触发的就是 performSyncWorkOnRoot。performSyncWorkOnRoot 开启的正是我们反复强调的 render 阶段;而 commitRoot 方法开启的则是真实 DOM 的渲染过程(commit 阶段)。因此以 scheduleUpdateOnFiber 和 commitRoot 两个方法为界,我们可以大致把 ReactDOM.render 的调用栈划分为三个阶段:
- 初始化阶段
render阶段commit阶段
# 二、初始化阶段
# 拆解 ReactDOM.render 调用栈——初始化阶段
首先我们提取出初始化过程中涉及的调用栈大图:

图中的方法虽然看上去又多又杂,但做的事情清清爽爽,那就是完成 Fiber 树中基本实体的创建。
什么是基本实体?基本实体有哪些?问题的答案藏在源码里,这里我为你提取了源码中的关键逻辑,首先是 legacyRenderSubtreeIntoContainer 方法。在 ReactDOM.render 函数体中,以下面代码所示的姿势调用了它:
return legacyRenderSubtreeIntoContainer(null, element, container, false, callback);
而 legacyRenderSubtreeIntoContainer 的关键逻辑如下(解析在注释里):
function legacyRenderSubtreeIntoContainer(parentComponent, children, container, forceHydrate, callback) {
// container 对应的是我们传入的真实 DOM 对象
var root = container._reactRootContainer;
// 初始化 fiberRoot 对象
var fiberRoot;
// DOM 对象本身不存在 _reactRootContainer 属性,因此 root 为空
if (!root) {
// 若 root 为空,则初始化 _reactRootContainer,并将其值赋值给 root
root = container._reactRootContainer = legacyCreateRootFromDOMContainer(container, forceHydrate);
// legacyCreateRootFromDOMContainer 创建出的对象会有一个 _internalRoot 属性,将其赋值给 fiberRoot
fiberRoot = root._internalRoot;
// 这里处理的是 ReactDOM.render 入参中的回调函数,你了解即可
if (typeof callback === 'function') {
var originalCallback = callback;
callback = function () {
var instance = getPublicRootInstance(fiberRoot);
originalCallback.call(instance);
};
} // Initial mount should not be batched.
// 进入 unbatchedUpdates 方法
unbatchedUpdates(function () {
updateContainer(children, fiberRoot, parentComponent, callback);
});
} else {
// else 逻辑处理的是非首次渲染的情况(即更新),其逻辑除了跳过了初始化工作,与楼上基本一致
fiberRoot = root._internalRoot;
if (typeof callback === 'function') {
var _originalCallback = callback;
callback = function () {
var instance = getPublicRootInstance(fiberRoot);
_originalCallback.call(instance);
};
} // Update
updateContainer(children, fiberRoot, parentComponent, callback);
}
return getPublicRootInstance(fiberRoot);
}
这里我为你总结一下首次渲染过程中 legacyRenderSubtreeIntoContainer 方法的主要逻辑链路:

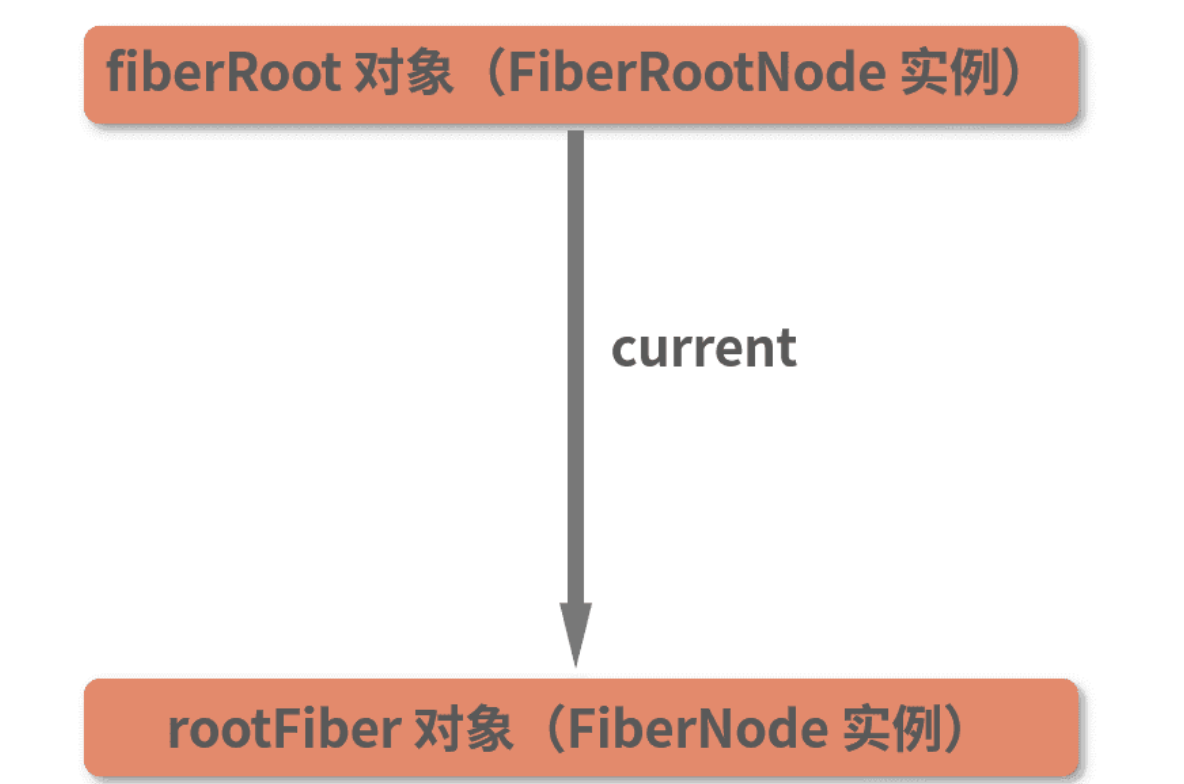
在这个流程中,你需要关注到 fiberRoot 这个对象。fiberRoot 到底是什么呢?这里我将运行时的 root 和 fiberRoot为你截取出来,其中 root 对象的结构如下图所示:
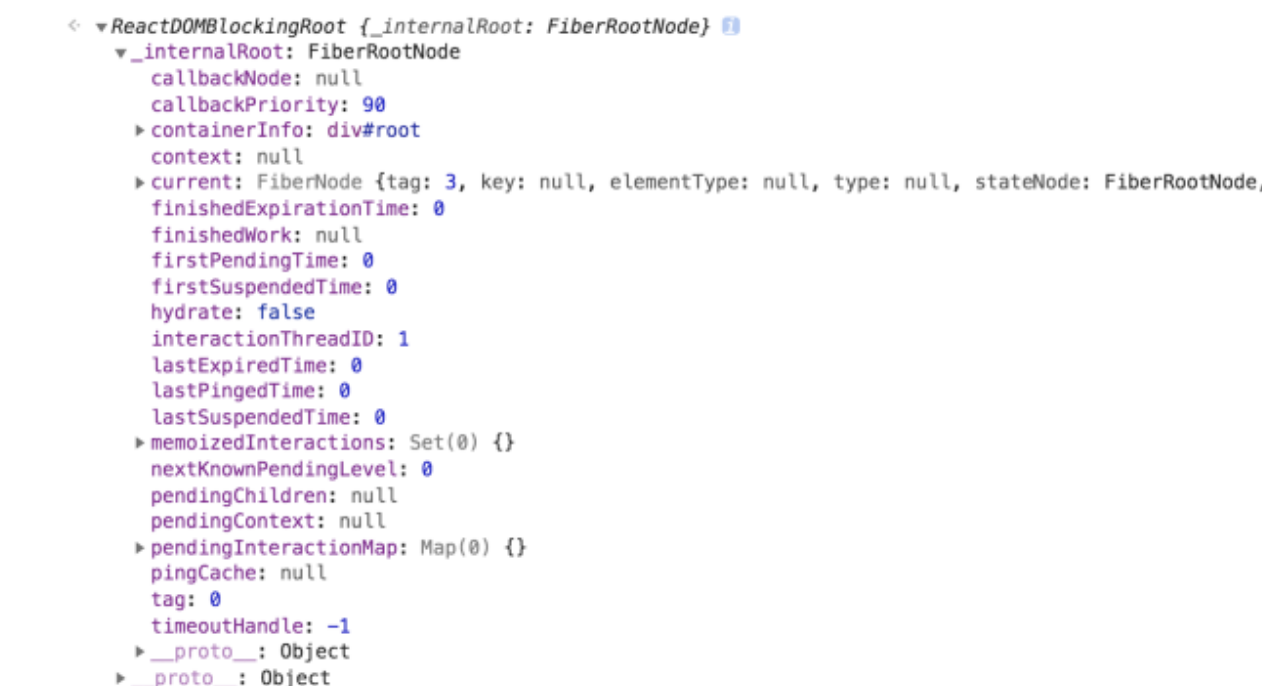
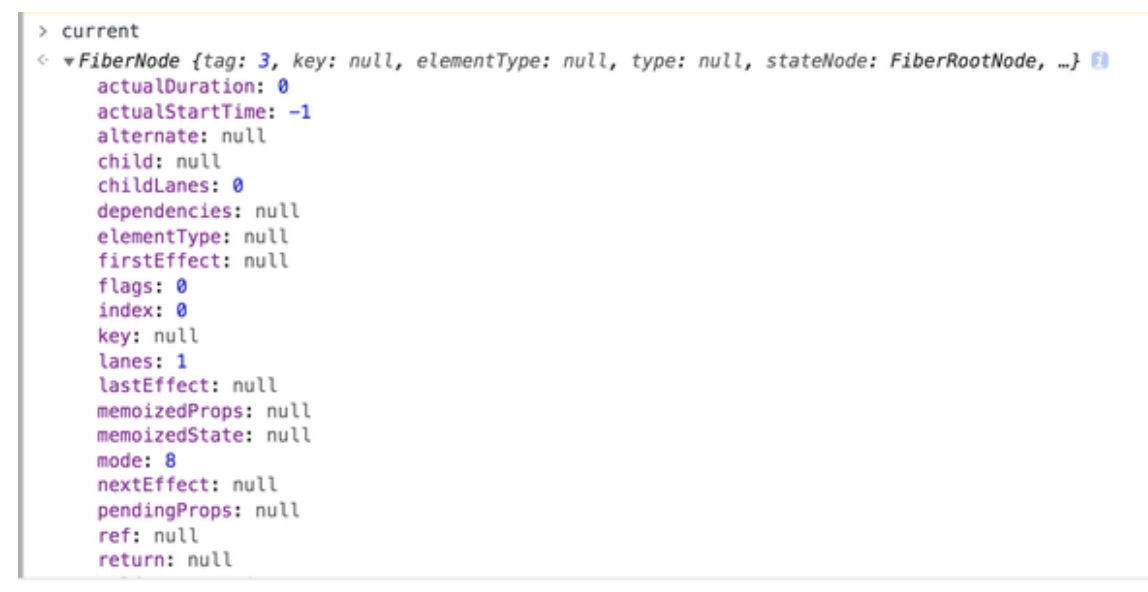
可以看出,root 对象(container._reactRootContainer)上有一个 _internalRoot 属性,这个 _internalRoot 也就是 fiberRoot。fiberRoot 的本质是一个 FiberRootNode 对象,其中包含一个 current 属性,该属性同样需要划重点。这里我为你高亮出 current 属性的部分内容:
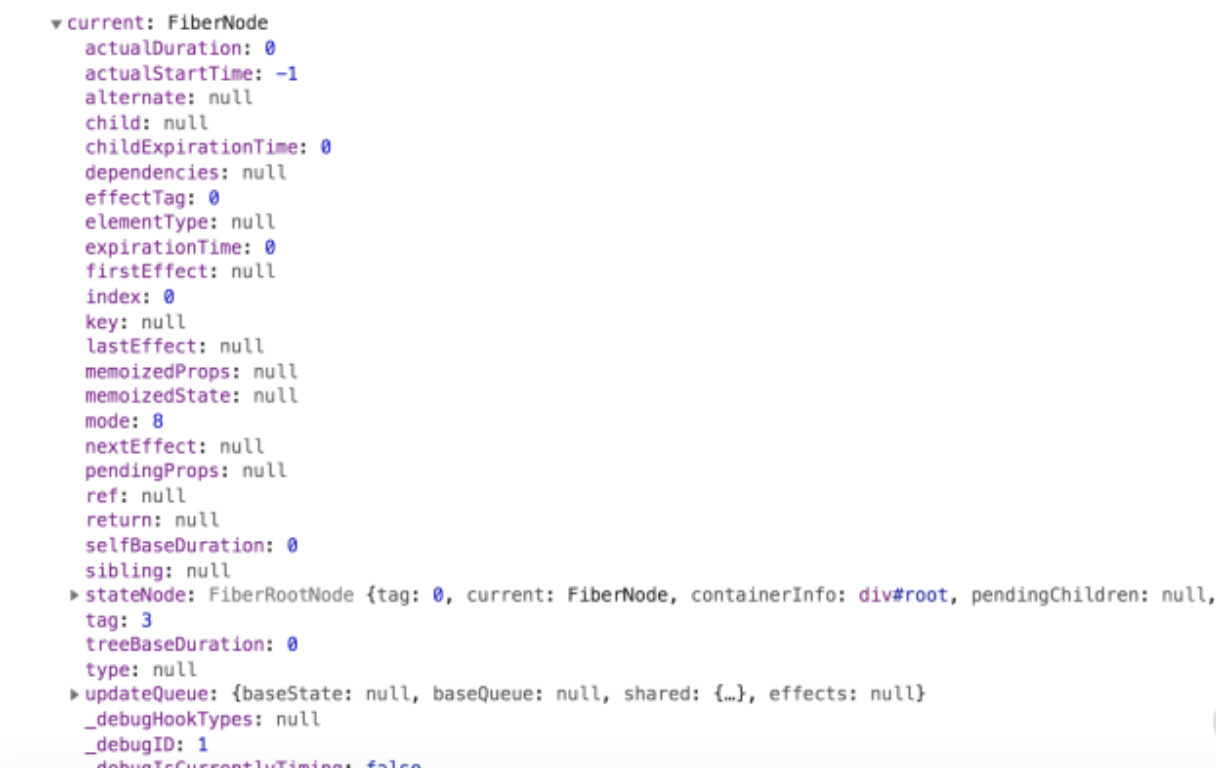
或许你会对
current对象包含的海量属性感到陌生和头大,但这并不妨碍你 Get 到“current 对象是一个 FiberNode 实例”这一点,FiberNode,正是Fiber节点对应的对象类型。current对象是一个Fiber节点,不仅如此,它还是当前Fiber树的头部节点
考虑到 current 属性对应的 FiberNode 节点,在调用栈中实际是由 createHostRootFiber 方法创建的,React 源码中也有多处以 rootFiber 代指 current 对象,因此下文中我们将以 rootFiber 指代 current 对象。
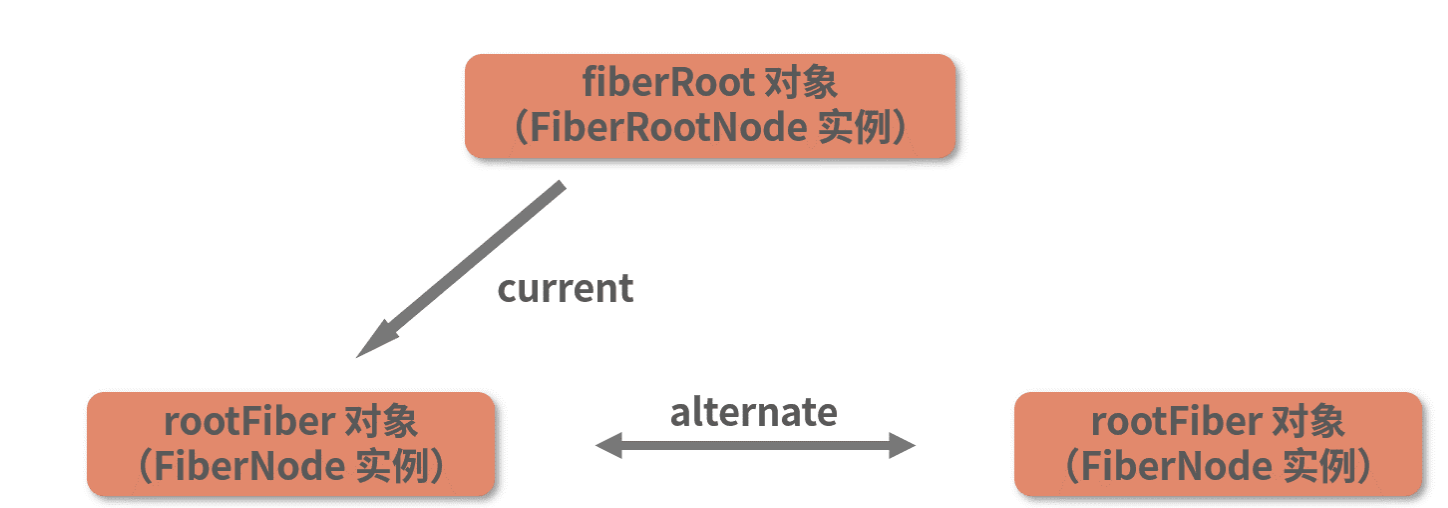
读到这里,你脑海中应该不难形成一个这样的指向关系:
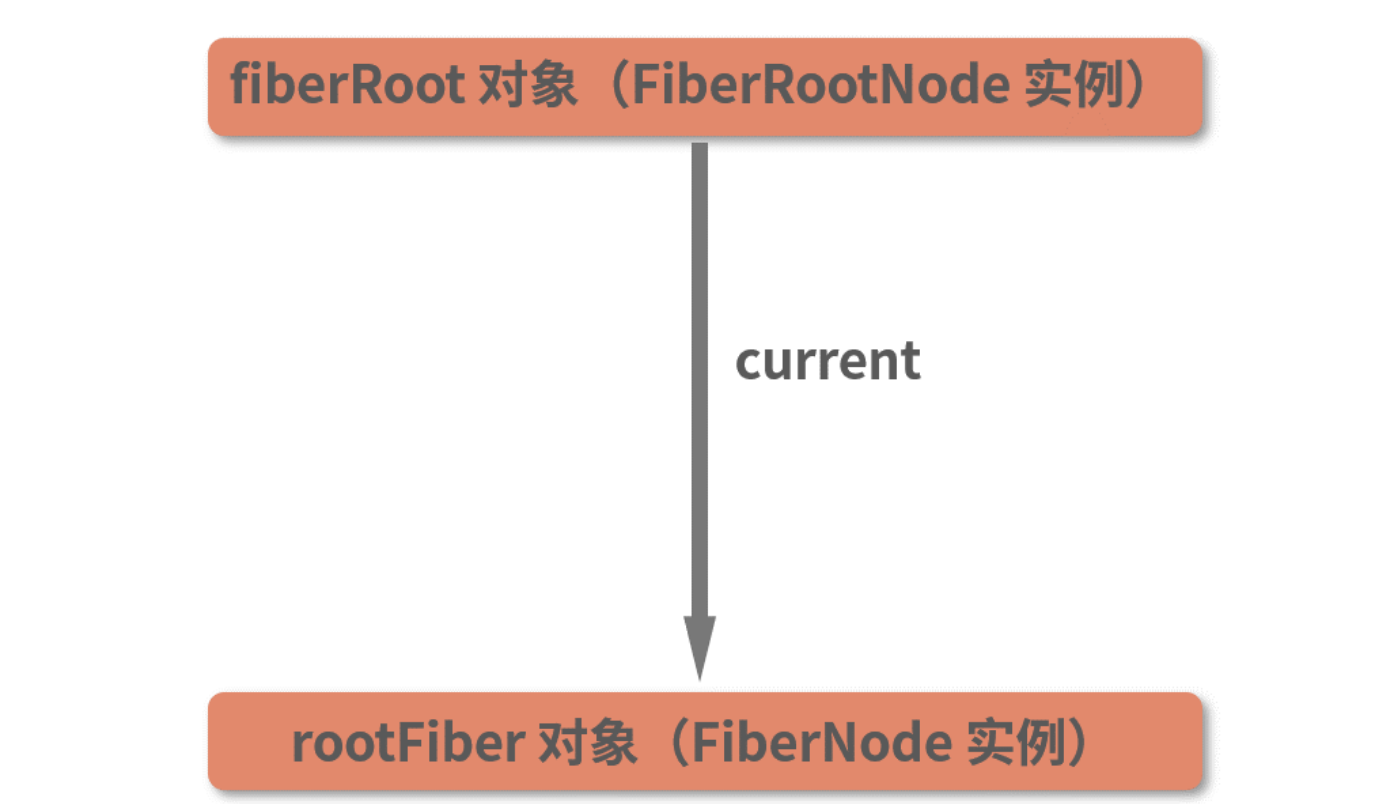
其中,fiberRoot 的关联对象是真实 DOM 的容器节点;而 rootFiber 则作为虚拟 DOM 的根节点存在。这两个节点,将是后续整棵 Fiber 树构建的起点。
接下来,fiberRoot 将和 ReactDOM.render 方法的其他入参一起,被传入 updateContainer 方法,从而形成一个回调。这个回调,正是接下来要调用的 unbatchedUpdates 方法的入参。我们一起看看 unbatchedUpdates 做了什么,下面代码是对 unbatchedUpdates 主体逻辑的提取:
function unbatchedUpdates(fn, a) {
// 这里是对上下文的处理,不必纠结
var prevExecutionContext = executionContext;
executionContext &= ~BatchedContext;
executionContext |= LegacyUnbatchedContext;
try {
// 重点在这里,直接调用了传入的回调函数 fn,对应当前链路中的 updateContainer 方法
return fn(a);
} finally {
// finally 逻辑里是对回调队列的处理,此处不用太关注
executionContext = prevExecutionContext;
if (executionContext === NoContext) {
// Flush the immediate callbacks that were scheduled during this batch
resetRenderTimer();
flushSyncCallbackQueue();
}
}
}
在 unbatchedUpdates 函数体里,当下你只需要 Get 到一个信息:它直接调用了传入的回调 fn。而在当前链路中,fn 是什么呢?fn 是一个针对 updateContainer 的调用:
unbatchedUpdates(function () {
updateContainer(children, fiberRoot, parentComponent, callback);
});
接下来我们很有必要去看看 updateContainer 里面的逻辑。这里我将主体代码提取如下(解析在注释里,如果没有耐心读完可以直接看文字解读):
function updateContainer(element, container, parentComponent, callback) {
......
// 这是一个 event 相关的入参,此处不必关注
var eventTime = requestEventTime();
......
// 这是一个比较关键的入参,lane 表示优先级
var lane = requestUpdateLane(current$1);
// 结合 lane(优先级)信息,创建 update 对象,一个 update 对象意味着一个更新
var update = createUpdate(eventTime, lane);
// update 的 payload 对应的是一个 React 元素
update.payload = {
element: element
};
// 处理 callback,这个 callback 其实就是我们调用 ReactDOM.render 时传入的 callback
callback = callback === undefined ? null : callback;
if (callback !== null) {
{
if (typeof callback !== 'function') {
error('render(...): Expected the last optional `callback` argument to be a ' + 'function. Instead received: %s.', callback);
}
}
update.callback = callback;
}
// 将 update 入队
enqueueUpdate(current$1, update);
// 调度 fiberRoot
scheduleUpdateOnFiber(current$1, lane, eventTime);
// 返回当前节点(fiberRoot)的优先级
return lane;
}
updateContainer 的逻辑相对来说丰富了点,但大部分逻辑也是在干杂活,它做的最关键的事情可以总结为三件:
- 请求当前
Fiber节点的 lane(优先级); - 结合
lane(优先级),创建当前Fiber节点的update对象,并将其入队; - 调度当前节点(
rootFiber)。
函数体中的 scheduleWork 其实就是 scheduleUpdateOnFiber,scheduleUpdateOnFiber 函数的任务是调度当前节点的更新。在这个函数中,会处理一系列与优先级、打断操作相关的逻辑。但是在 ReactDOM.render 发起的首次渲染链路中,这些意义都不大,因为这个渲染过程其实是同步的。我们可以尝试在 Source 面板中为该函数打上断点,逐行执行代码,会发现逻辑最终会走到下图的高亮处:
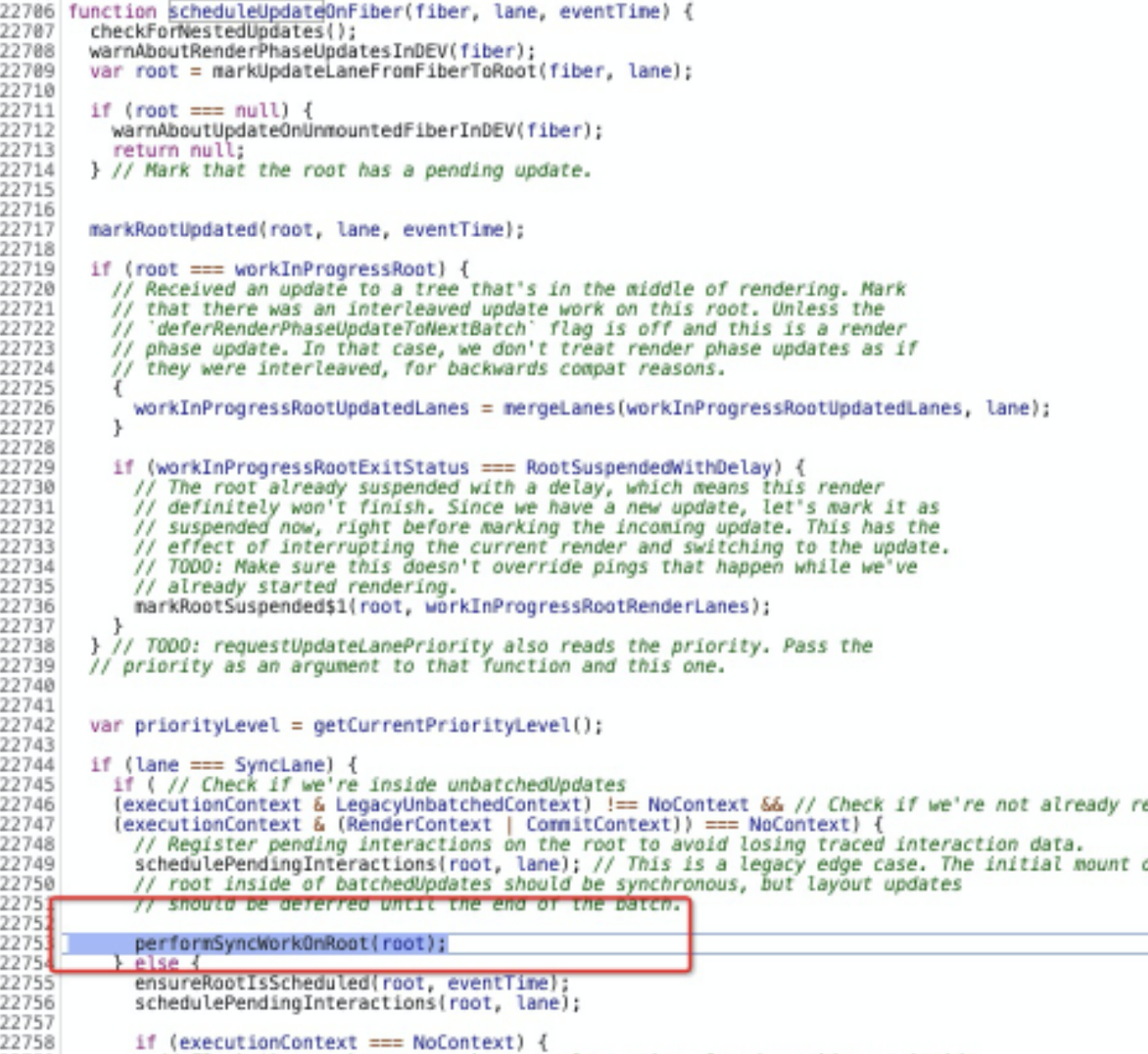
performSyncWorkOnRoot直译过来就是“执行根节点的同步任务”,这里的“同步”二字需要注意,它明示了接下来即将开启的是一个同步的过程。这也正是为什么在整个渲染链路中,调度(Schedule)动作没有存在感的原因。
前面我们曾经提到过,performSyncWorkOnRoot 是 render 阶段的起点,render 阶段的任务就是完成 Fiber 树的构建,它是整个渲染链路中最核心的一环。在异步渲染的模式下,render 阶段应该是一个可打断的异步过程
而现在,我相信你心里更多的疑惑在于:
都说 Fiber 架构带来的异步渲染是 React 16 的亮点,为什么分析到现在,竟然发现 ReactDOM.render 触发的首次渲染是个同步过程呢
# 同步的 ReactDOM.render,异步的 ReactDOM.createRoot
其实在 React 16,包括近期发布的 React 17 小版本中,React 都有以下 3 种启动方式:
legacy 模式:
ReactDOM.render(<App />, rootNode)。这是当前 React App 使用的方式,当前没有计划删除本模式,但是这个模式可能不支持这些新功能。
blocking 模式:
ReactDOM.createBlockingRoot(rootNode).render(<App />)。目前正在实验中,作为迁移到 concurrent 模式的第一个步骤
concurrent 模式:
ReactDOM.createRoot(rootNode).render(<App />)。目前在实验中,未来稳定之后,打算作为 React的默认开发模式,这个模式开启了所有的新功能
在这 3 种模式中,
我们常用的 ReactDOM.render 对应的是 legacy 模式,它实际触发的仍然是同步的渲染链路。blocking模式可以理解为legacy和concurrent之间的一个过渡形态,之所以会有这个模式,是因为 React 官方希望能够提供渐进的迁移策略,帮助我们更加顺滑地过渡到Concurrent模式。blocking在实际应用中是比较低频的一个模式,了解即可。
按照官方的说法,“长远来看,模式的数量会收敛,不用考虑不同的模式,但就目前而言,模式是一项重要的迁移策略,让每个人都能决定自己什么时候迁移,并按照自己的速度进行迁移”。由此可以看出,Concurrent 模式确实是 React 的终极目标,也是其创作团队使用 Fiber 架构重写核心算法的动机所在。
# 拓展:关于异步模式下的首次渲染链路
当下,如果想要开启异步渲染,我们需要调用 ReactDOM.createRoot 方法来启动应用,那 ReactDOM.createRoot 开启的渲染链路与 ReactDOM.render 有何不同呢?
这里我修改一下调用方式,给你展示一下调用栈。由于本讲的源码取材于 React 17.0.0 版本,在这个版本中,createRoot 仍然是一个 unstable 的方法。因此实际调用的 API 应该是“unstable_createRoot”:
ReactDOM.unstable_createRoot(rootElement).render(<App />);
Concurrent 模式开启后,首次渲染的调用栈变成了如下图所示的样子:

乍一看,好像和 ReactDOM.render 差别很大,其实不然。图中 createRoot 所触发的逻辑仍然是一些准备性质的初始化工作,此处不必太纠结。关键在于下面我给你框出来的这部分,如下图所示
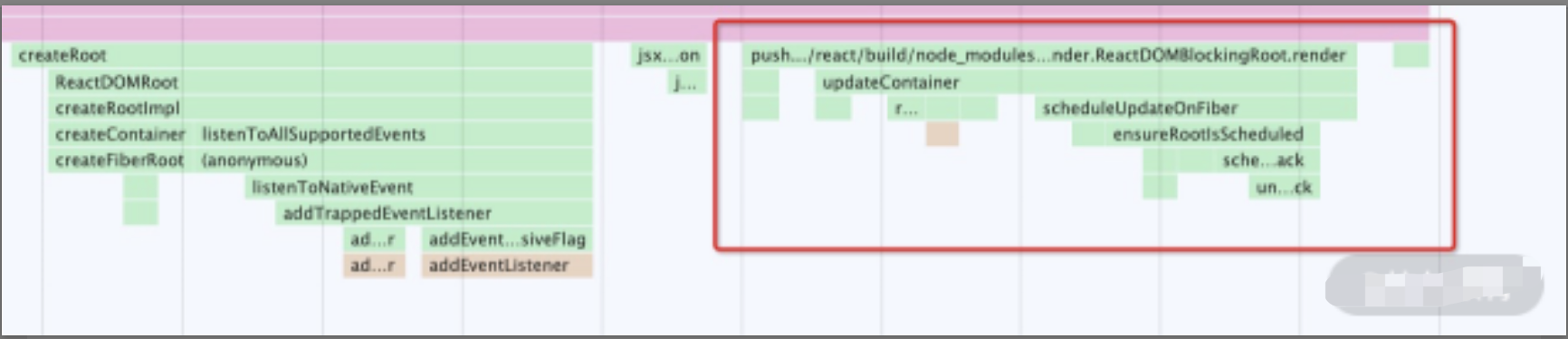
我们拉近一点来看,如下图所示:

你会发现这地方也调用了一个 render。再顺着这个调用往下看,发现有大量的熟悉面孔:updateContainer、requestUpdateLane、createUpdate、scheduleUpdateOnFiber......这些函数在 ReactDOM.render 的调用栈中也出现过。
其实,当前你看到的这个 render 调用链路,和 ReactDOM.render 的调用链路是非常相似的,主要的区别在 scheduleUpdateOnFiber 的这个判断里:

在异步渲染模式下,由于请求到的 lane 不再是 SyncLane(同步优先级),故不会再走到 performSyncWorkOnRoot 这个调用,而是会转而执行 else 中调度相关的逻辑。
这里有个点要给你点出来——React 是如何知道当前处于哪个模式的呢?我们可以以 requestUpdateLane 函数为例,下面是它局部的代码:
function requestUpdateLane(fiber) {
// 获取 mode 属性
var mode = fiber.mode;
// 结合 mode 属性判断当前的
if ((mode & BlockingMode) === NoMode) {
return SyncLane;
} else if ((mode & ConcurrentMode) === NoMode) {
return getCurrentPriorityLevel() === ImmediatePriority$1 ? SyncLane : SyncBatchedLane;
}
......
return lane;
}
上面代码中需要注意 fiber节点上的 mode 属性:React 将会通过修改 mode 属性为不同的值,来标识当前处于哪个渲染模式;在执行过程中,也是通过判断这个属性,来区分不同的渲染模式。
因此不同的渲染模式在挂载阶段的差异,本质上来说并不是工作流的差异(其工作流涉及 初始化 → render → commit 这 3 个步骤),而是 mode 属性的差异。
mode 属性决定着这个工作流是一气呵成(同步)的,还是分片执行(异步)的
# Fiber 架构一定是异步渲染吗?
React 16 如果没有开启 Concurrent 模式,那它还能叫 Fiber 架构吗?
从动机上来看,Fiber 架构的设计确实主要是为了 Concurrent 而存在。但经过了本讲紧贴源码的讲解,相信你也能够看出,在 React 16,包括已发布的 React 17 版本中,不管是否是 Concurrent,整个数据结构层面的设计、包括贯穿整个渲染链路的处理逻辑,已经完全用 Fiber 重构了一遍。站在这个角度来看,Fiber 架构在 React 中并不能够和异步渲染画严格的等号,它是一种同时兼容了同步渲染与异步渲染的设计。
# 三、render 阶段
# 拆解 ReactDOM.render 调用栈——render 阶段
首先,我们复习一下 render 阶段在整个渲染链路中的定位,如下图所示。

图中,performSyncWorkOnRoot 标志着 render 阶段的开始,finishSyncRender 标志着 render阶段的结束。这中间包含了大量的 beginWork、completeWork 调用栈,正是 render 的工作内容。
beginWork、completeWork这两个方法需要注意,它们串联起的是一个“模拟递归”的过程。
React 15 下的调和过程是一个递归的过程。而 Fiber 架构下的调和过程,虽然并不是依赖递归来实现的,但在 ReactDOM.render 触发的同步模式下,它仍然是一个深度优先搜索的过程。在这个过程中,beginWork 将创建新的 Fiber 节点,而 completeWork 则负责将 Fiber 节点映射为 DOM 节点。
我们的 Fiber 树都还长这个样子:
就这么个样子,你遍历它,能遍历出来什么?到底怎么个遍历法?接下来我们就深入到源码里去一探究竟!
# workInProgress 节点的创建
performSyncWorkOnRoot 是 render 阶段的起点,而这个函数最关键的地方在于它调用了 renderRootSync。下面我们放大 Performance 调用栈,来看看 renderRootSync 被调用后,紧接着发生了什么:

紧随其后的是 prepareFreshStack,这里不卖关子,prepareFreshStack 的作用是重置一个新的堆栈环境,其中最需要我们关注的步骤,就是对createWorkInProgress 的调用。以下我对 createWorkInProgress 的主要逻辑进行了提取(解析在注释里):
// 这里入参中的 current 传入的是现有树结构中的 rootFiber 对象
function createWorkInProgress(current, pendingProps) {
var workInProgress = current.alternate;
// ReactDOM.render 触发的首屏渲染将进入这个逻辑
if (workInProgress === null) {
// 这是需要你关注的第一个点,workInProgress 是 createFiber 方法的返回值
workInProgress = createFiber(current.tag, pendingProps, current.key, current.mode);
workInProgress.elementType = current.elementType;
workInProgress.type = current.type;
workInProgress.stateNode = current.stateNode;
// 这是需要你关注的第二个点,workInProgress 的 alternate 将指向 current
workInProgress.alternate = current;
// 这是需要你关注的第三个点,current 的 alternate 将反过来指向 workInProgress
current.alternate = workInProgress;
} else {
// else 的逻辑此处先不用关注
}
// 以下省略大量 workInProgress 对象的属性处理逻辑
// 返回 workInProgress 节点
return workInProgress;
}
首先要声明的是,该函数中的 current 入参指的是现有树结构中的 rootFiber 对象,如下图所示:
源码太长(其实经过处理已经不长了)不看版的重点如下:
createWorkInProgress将调用createFiber,workInProgress是createFiber方法的返回值;workInProgress的alternate将指向current;current的alternate将反过来指向workInProgress。
理解了这三点,你就会自然而然地想知道 workInProgress 的本体到底是什么样的,也就是 createFiber 到底会返回什么。下面我们就看看 createFiber 的逻辑:
var createFiber = function (tag, pendingProps, key, mode) {
return new FiberNode(tag, pendingProps, key, mode);
};
代码出奇的简单,但信息却给得很到位 —— createFiber 将创建一个 FiberNode 实例,而 FiberNode,它正是 Fiber 节点的类型。因此 workInProgress 就是一个 Fiber 节点。不仅如此,细心的你可能还会发现 workInProgress 的创建入参其实来源于 current,如下面代码所示:
workInProgress = createFiber(current.tag, pendingProps, current.key, current.mode);
workInProgress 节点其实就是 current 节点(即 rootFiber)的副本
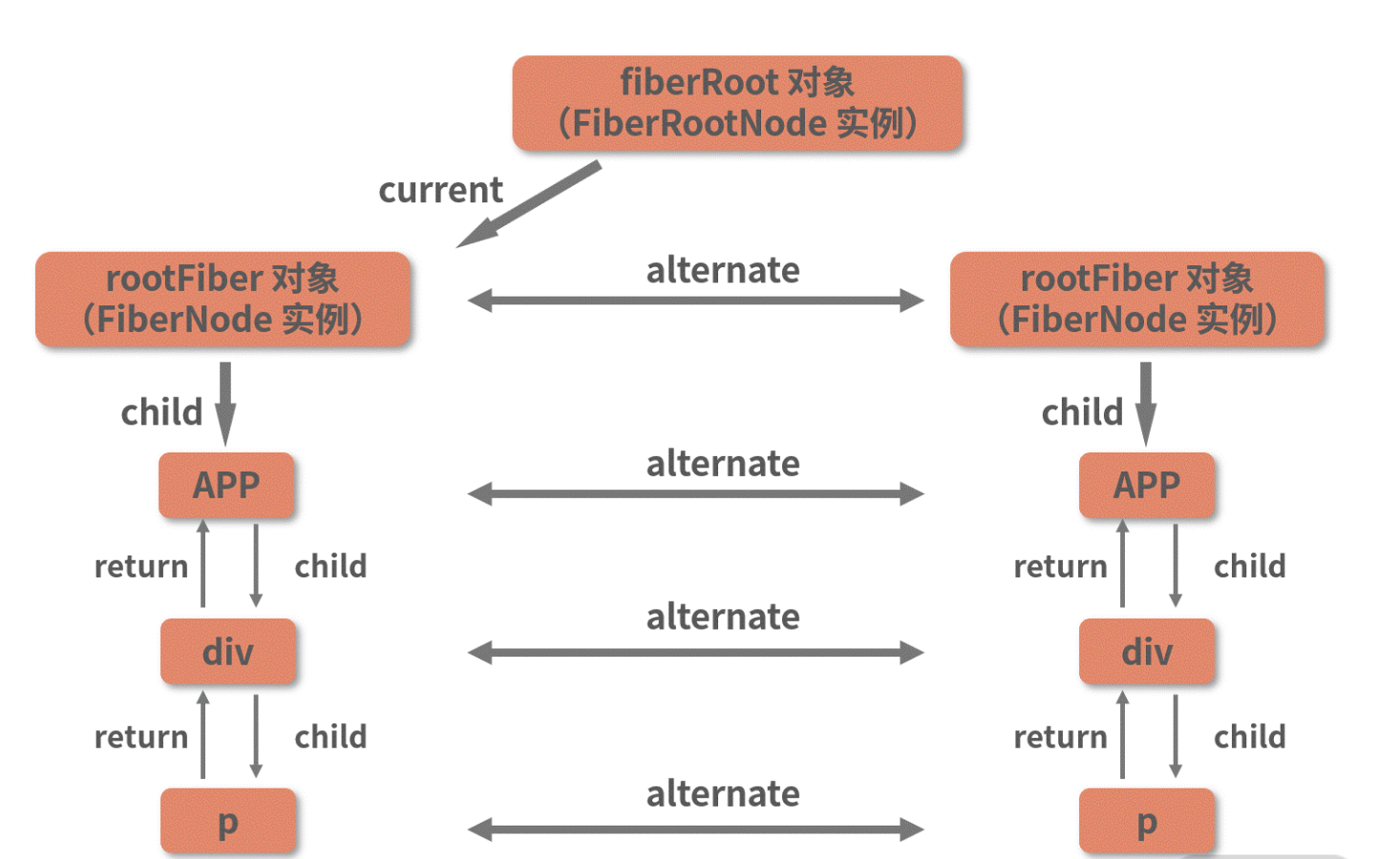
再结合 current 指向 rootFiber 对象(同样是 FiberNode 实例),以及 current 和 workInProgress 通过 alternate 互相连接这些信息,我们可以分析出这波操作执行完之后,整棵树的结构应该如下图所示:
完成了这个任务之后,就会进入 workLoopSync 的逻辑。这个 workLoopSync 函数也是个“人狠话不多”的主,它的逻辑同样是简洁明了的,如下所示(解析在注释里):
function workLoopSync() {
// 若 workInProgress 不为空
while (workInProgress !== null) {
// 针对它执行 performUnitOfWork 方法
performUnitOfWork(workInProgress);
}
}
workLoopSync 做的事情就是通过 while 循环反复判断 workInProgress 是否为空,并在不为空的情况下针对它执行 performUnitOfWork 函数。
而
performUnitOfWork函数将触发对beginWork的调用,进而实现对新Fiber节点的创建。若beginWork所创建的Fiber节点不为空,则performUniOfWork会用这个新的Fiber节点来更新workInProgress的值,为下一次循环做准备。
通过循环调用 performUnitOfWork 来触发 beginWork,新的 Fiber 节点就会被不断地创建。当 workInProgress 终于为空时,说明没有新的节点可以创建了,也就意味着已经完成对整棵 Fiber 树的构建。
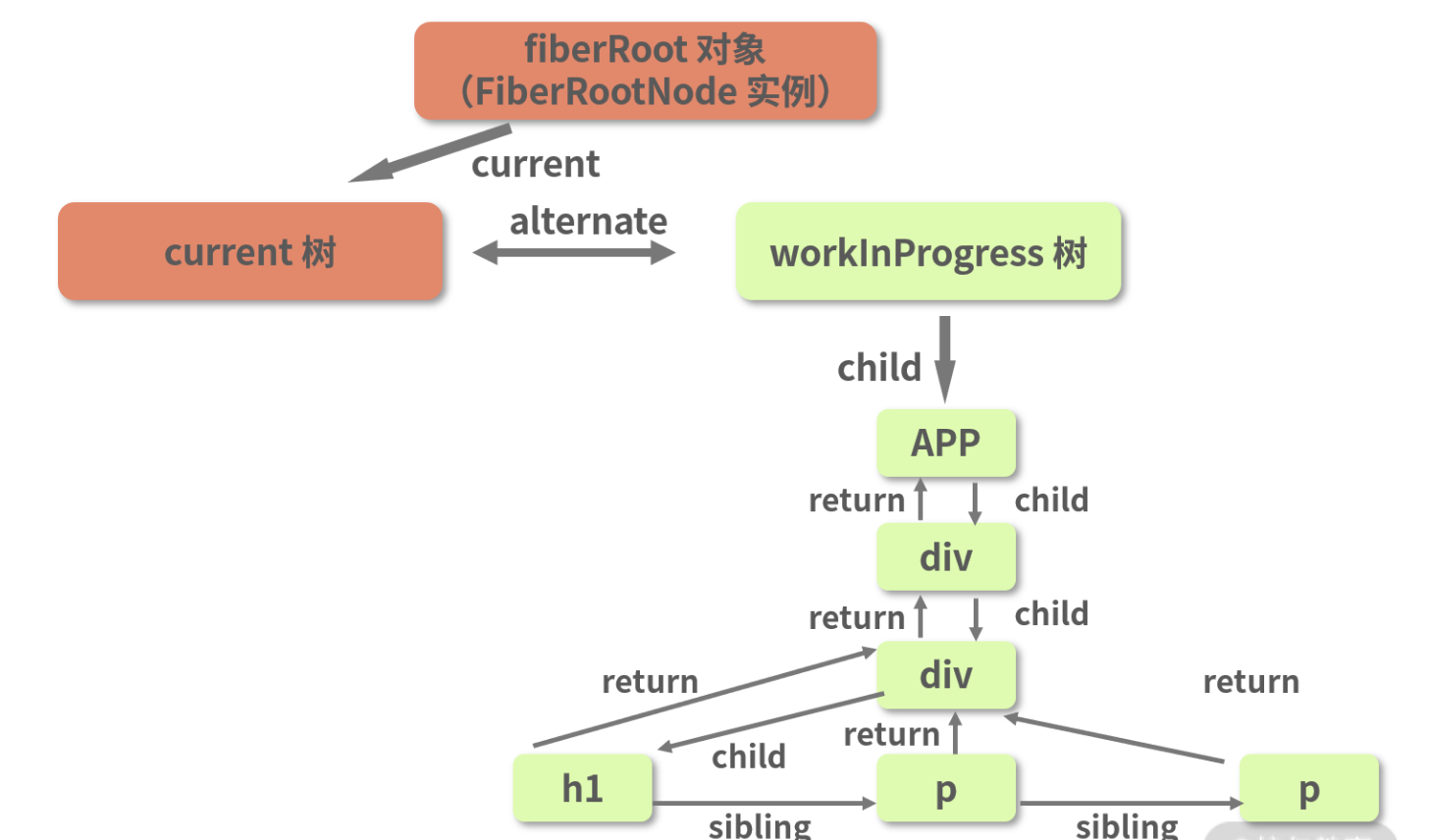
在这个过程中,每一个被创建出来的新 Fiber 节点,都会一个一个挂载为最初那个 workInProgress 节点(如下图高亮处)的后代节点。而上述过程中构建出的这棵 Fiber 树,也正是大名鼎鼎的 workInProgress 树。
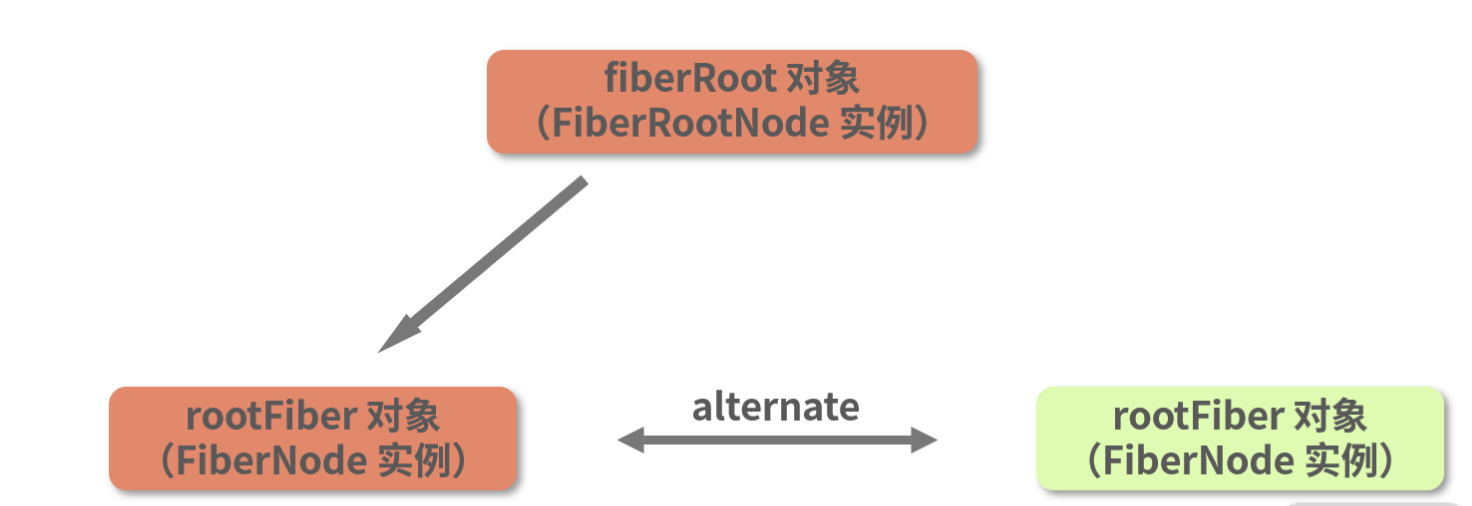
相应地,图中 current 指针所指向的根节点所在的那棵树,我们叫它“current 树”。
相应地,图中 current 指针所指向的根节点所在的那棵树,我们叫它“current 树”。
这时候,相信一些同学心里已经开始犯嘀咕了:一棵 current 树,一棵 workInProgress 树,这名堂也太多了吧!况且这两棵 Fiber 树至少在现在看来,是完全没区别的(毕竟都还只有一个根节点,哈哈)。React 这样设计的目的何在?或者换个问法——到底是什么样的事情一棵树做不到,非得搞两棵“一样”的树出来?
在一步一步理解 Fiber 树的构建和更新过程之后,我将带你去认识“两棵 Fiber 树”这一现象背后的动机。
接下来我们就深入到 beginWork 和 completeWork 的逻辑里去,一起看看 Fiber 树的构建过程及最终形态。
# beginWork 开启 Fiber 节点创建过程
有一说一,beginWork 的源码实在是长到不科学。这里我们本着抓主要矛盾的原则,针对与树构建过程强相关的动作进行逻辑提取,代码如下(解析在注释里):
function beginWork(current, workInProgress, renderLanes) {
......
// current 节点不为空的情况下,会加一道辨识,看看是否有更新逻辑要处理
if (current !== null) {
// 获取新旧 props
var oldProps = current.memoizedProps;
var newProps = workInProgress.pendingProps;
// 若 props 更新或者上下文改变,则认为需要"接受更新"
if (oldProps !== newProps || hasContextChanged() || (
workInProgress.type !== current.type )) {
// 打个更新标
didReceiveUpdate = true;
} else if (xxx) {
// 不需要更新的情况 A
return A
} else {
if (需要更新的情况 B) {
didReceiveUpdate = true;
} else {
// 不需要更新的其他情况,这里我们的首次渲染就将执行到这一行的逻辑
didReceiveUpdate = false;
}
}
} else {
didReceiveUpdate = false;
}
......
// 这坨 switch 是 beginWork 中的核心逻辑,原有的代码量相当大
switch (workInProgress.tag) {
......
// 这里省略掉大量形如"case: xxx"的逻辑
// 根节点将进入这个逻辑
case HostRoot:
return updateHostRoot(current, workInProgress, renderLanes)
// dom 标签对应的节点将进入这个逻辑
case HostComponent:
return updateHostComponent(current, workInProgress, renderLanes)
// 文本节点将进入这个逻辑
case HostText:
return updateHostText(current, workInProgress)
......
// 这里省略掉大量形如"case: xxx"的逻辑
}
// 这里是错误兜底,处理 switch 匹配不上的情况
{
{
throw Error(
"Unknown unit of work tag (" +
workInProgress.tag +
"). This error is likely caused by a bug in React. Please file an issue."
)
}
}
}
beginWork 源码太长不看版的重点总结:
beginWork的入参是一对用alternate连接起来的workInProgress和current节点;beginWork的核心逻辑是根据fiber节点(workInProgress)的tag属性的不同,调用不同的节点创建函数。
当前的 current 节点是 rootFiber,而 workInProgress 则是 current 的副本,它们的 tag 都是 3,如下图所示:

而 3 正是 HostRoot 所对应的值,因此第一个 beginWork 将进入 updateHostRoot 的逻辑。
这里你先不必急于关注 updateHostRoot 的逻辑细节。事实上,在整段 switch 逻辑里,包含的形如“update+类型名”这样的函数是非常多的
幸运的是,这些函数之间不仅命名形式一致,工作内容也相似。就 render 链路来说,它们共同的特性,就是都会通过调用 reconcileChildren 方法,生成当前节点的子节点。
reconcileChildren 的源码如下:
function reconcileChildren(current, workInProgress, nextChildren, renderLanes) {
// 判断 current 是否为 null
if (current === null) {
// 若 current 为 null,则进入 mountChildFibers 的逻辑
workInProgress.child = mountChildFibers(workInProgress, null, nextChildren, renderLanes);
} else {
// 若 current 不为 null,则进入 reconcileChildFibers 的逻辑
workInProgress.child = reconcileChildFibers(workInProgress, current.child, nextChildren, renderLanes);
}
}
从源码来看,reconcileChildren 也只是做逻辑的分发,具体的工作还要到 mountChildFibers 和 reconcileChildFibers 里去看。
# ChildReconciler,处理 Fiber 节点的幕后“操盘手”
那么这两个函数又是何方神圣呢?在源码中,我们可以觅得这样两个赋值语句:
var reconcileChildFibers = ChildReconciler(true);
var mountChildFibers = ChildReconciler(false);
原来 reconcileChildFibers 和 mountChildFibers 不仅名字相似,出处也一致。它们都是 ChildReconciler 这个函数的返回值,仅仅存在入参上的区别。而 ChildReconciler,则是一个实打实的“庞然大物”,其内部的逻辑量堪比 N 个 beginWork。这里我将关键要素提取如下(解析在注释里):
function ChildReconciler(shouldTrackSideEffects) {
// 删除节点的逻辑
function deleteChild(returnFiber, childToDelete) {
if (!shouldTrackSideEffects) {
// Noop.
return;
}
// 以下执行删除逻辑
}
......
// 单个节点的插入逻辑
function placeSingleChild(newFiber) {
if (shouldTrackSideEffects && newFiber.alternate === null) {
newFiber.flags = Placement;
}
return newFiber;
}
// 插入节点的逻辑
function placeChild(newFiber, lastPlacedIndex, newIndex) {
newFiber.index = newIndex;
if (!shouldTrackSideEffects) {
// Noop.
return lastPlacedIndex;
}
// 以下执行插入逻辑
}
......
// 此处省略一系列 updateXXX 的函数,它们用于处理 Fiber 节点的更新
// 处理不止一个子节点的情况
function reconcileChildrenArray(returnFiber, currentFirstChild, newChildren, lanes) {
......
}
// 此处省略一堆 reconcileXXXXX 形式的函数,它们负责处理具体的 reconcile 逻辑
function reconcileChildFibers(returnFiber, currentFirstChild, newChild, lanes) {
// 这是一个逻辑分发器,它读取入参后,会经过一系列的条件判断,调用上方所定义的负责具体节点操作的函数
}
// 将总的 reconcileChildFibers 函数返回
return reconcileChildFibers;
}
由于原本的代码量着实巨大,感兴趣的同学可以点开这个文件查看细节 (opens new window),此处我仅针对与主流程强相关的逻辑为你总结以下要点:
- 关键的入参
shouldTrackSideEffects,意为“是否需要追踪副作用”,因此reconcileChildFibers和mountChildFibers的不同,在于对副作用的处理不同; ChildReconciler中定义了大量如placeXXX、deleteXXX、updateXXX、reconcileXXX等这样的函数,这些函数覆盖了对Fiber节点的创建、增加、删除、修改等动作,将直接或间接地被reconcileChildFibers所调用;ChildReconciler的返回值是一个名为reconcileChildFibers的函数,这个函数是一个逻辑分发器,它将根据入参的不同,执行不同的 Fiber 节点操作,最终返回不同的目标 Fiber 节点。
对于第 1 点,这里展开说说。对副作用的处理不同,到底是哪里不同?以 placeSingleChild 为例,以下是 placeSingleChild 的源码:
function placeSingleChild(newFiber) {
if (shouldTrackSideEffects && newFiber.alternate === null) {
newFiber.flags = Placement;
}
return newFiber;
}
可以看出,一旦判断 shouldTrackSideEffects 为 false,那么下面所有的逻辑都不执行了,直接返回。那如果执行下去会发生什么呢?简而言之就是给 Fiber 节点打上一个叫“flags”的标记,像这样:
newFiber.flags = Placement;
这个名为 flags 的标记有何作用呢?
小科普:flags 是什么
由于这里我引用的是 v17.0.0 版本的源码,属性名已经变更为 flags,但在更早一些的版本中,这个属性名叫“effectTag”。在时下的社区讨论中,effectTag 这个命名更常见,也更语义化,因此下文我将以 “effectTag”代指“flags”。
Placement 这个 effectTag 的意义,是在渲染器执行时,也就是真实 DOM 渲染时,告诉渲染器:我这里需要新增 DOM 节点。 effectTag 记录的是副作用的类型,而所谓“副作用”,React 给出的定义是“数据获取、订阅或者修改 DOM”等动作。在这里,Placement 对应的显然是 DOM 相关的副作用操作。
像 Placement 这样的副作用标识,还有很多,它们均以二进制常量的形式存在,下图我为你截取了局部(你可以在这个文件里查看 effectTag 的类型):

回到我们的调用链路里来,由于 current 是 rootFiber,它不为 null,因此它将走入的是下图所高亮的这行逻辑。也就是说在 mountChildFibers 和 reconcileChildFibers 之间,它选择的是 reconcileChildFibers:
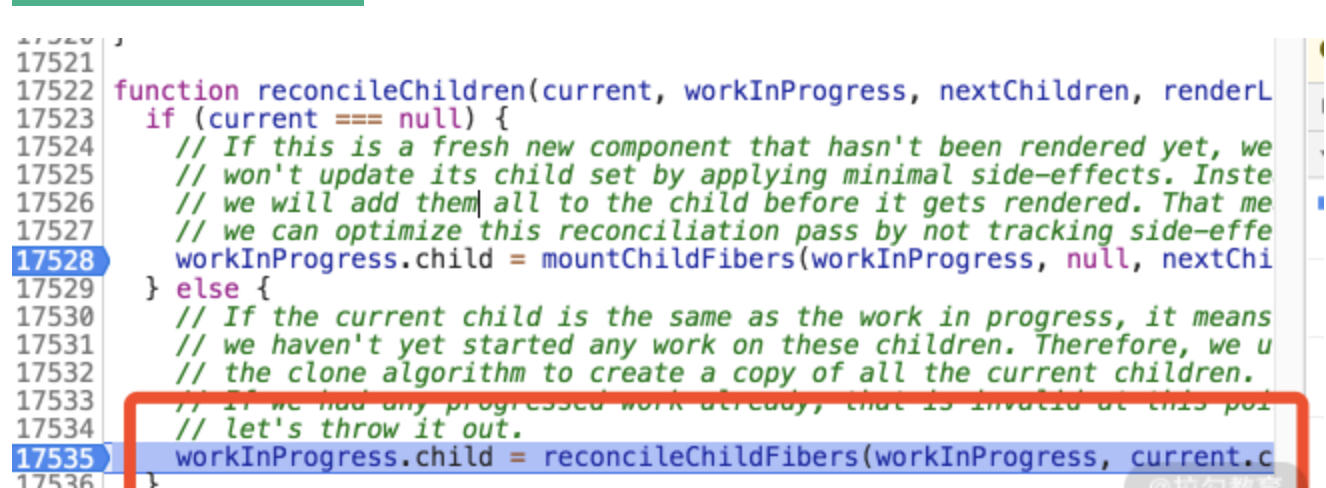
结合前面的分析可知,reconcileChildFibers 是ChildReconciler(true)的返回值。入参为 true,意味着其内部逻辑是允许追踪副作用的,因此“打 effectTag”这个动作将会生效。
接下来进入 reconcileChildFibers 的逻辑,在 reconcileChildFibers 这个逻辑分发器中,会把 rootFiber 子节点的创建工作分发给 reconcileXXX 函数家族的一员——reconcileSingleElement 来处理,具体的调用形式如下图高亮处所示:

reconcileSingleElement 将基于 rootFiber 子节点的 ReactElement 对象信息,创建其对应的 FiberNode。这个过程中涉及的函数调用如下图高亮处所示:
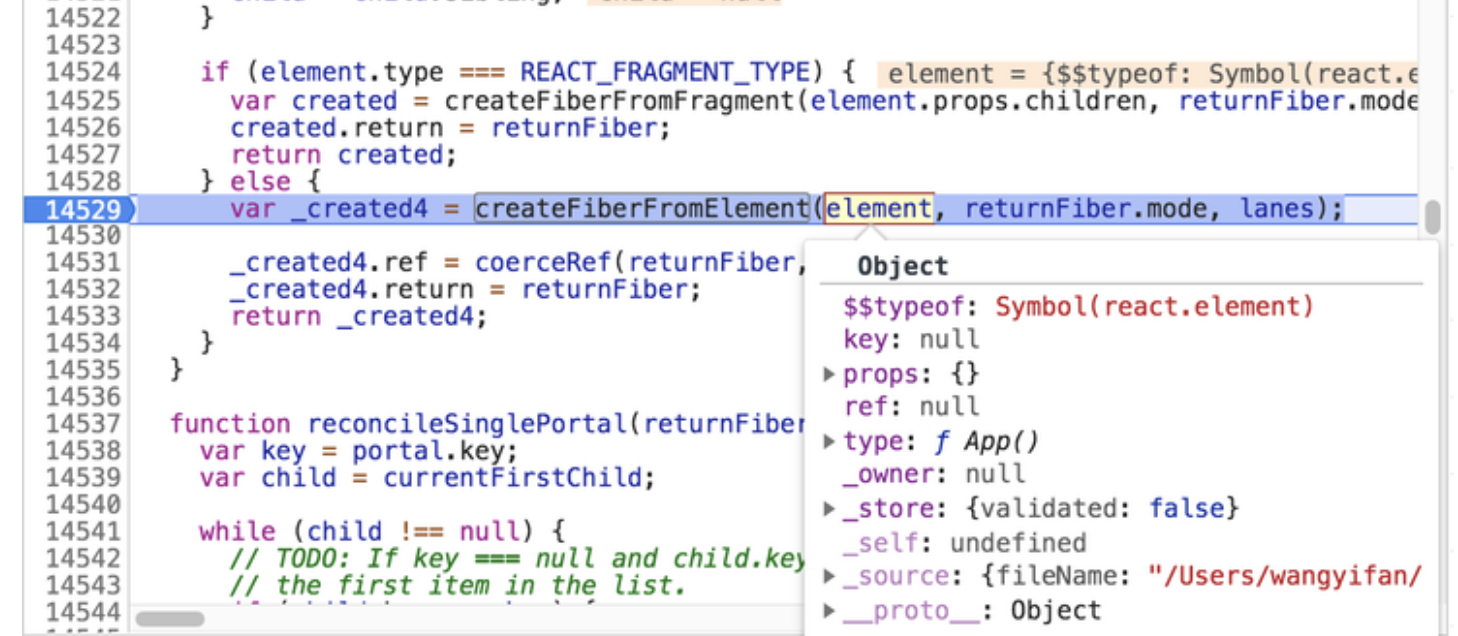
这里需要说明的一点是:rootFiber 作为 Fiber 树的根节点,它并没有一个确切的 ReactElement 与之映射。结合 JSX 结构来看,我们可以将其理解为是 JSX 中根组件的父节点。
import React from "react";
import ReactDOM from "react-dom";
function App() {
return (
<div className="App">
<div className="container">
<h1>我是标题</h1>
<p>我是第一段话</p>
<p>我是第二段话</p>
</div>
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
可以看出,根组件是一个类型为 App 的函数组件,因此 rootFiber 就是 App 的父节点。
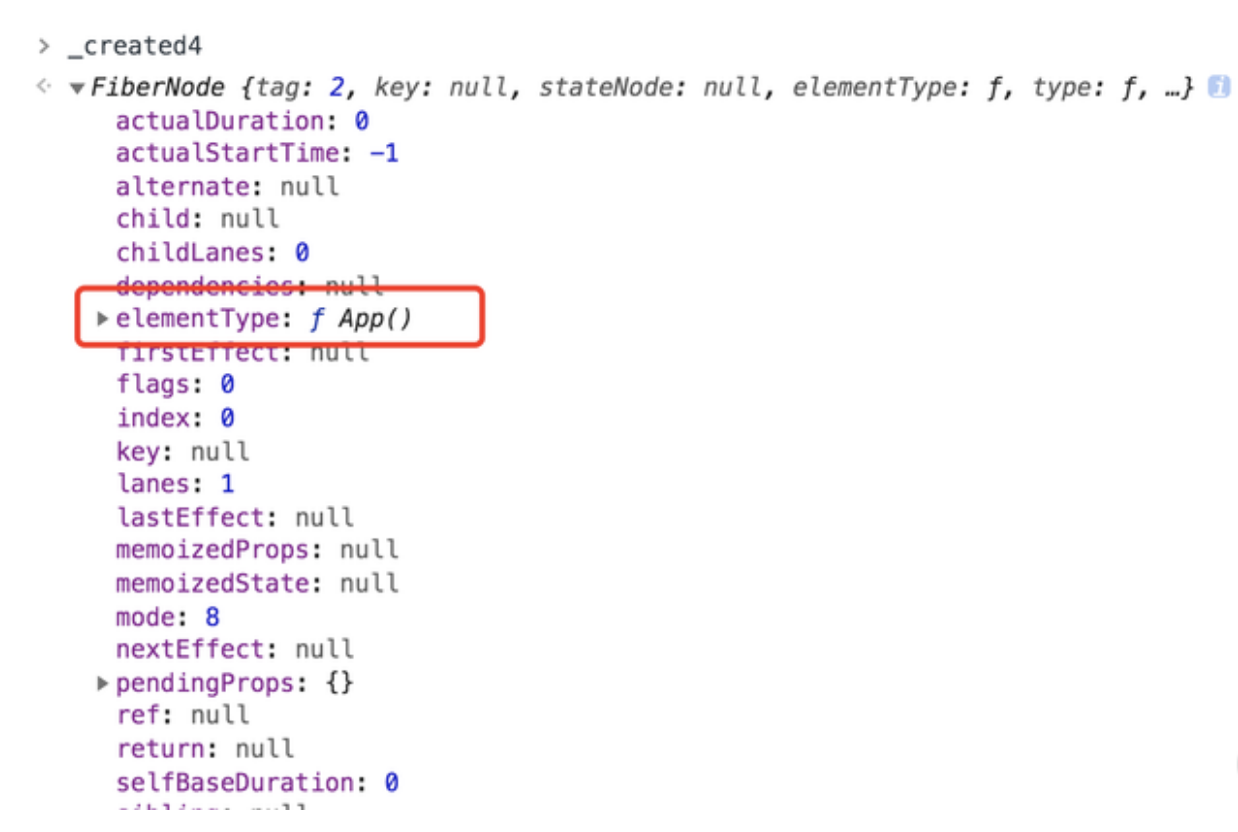
结合这个分析来看,图中的 _created4 是根据 rootFiber 的第一个子节点对应的 ReactElement 来创建的 Fiber 节点,那么它就是 App 所对应的 Fiber 节点。现在我为你打印出运行时的 _created4 值,会发现确实如此:
App 所对应的 Fiber 节点,将被 placeSingleChild 打上“Placement”(新增)的副作用标记,而后作为 reconcileChildFibers 函数的返回值,返回给下图中的 workInProgress.child:
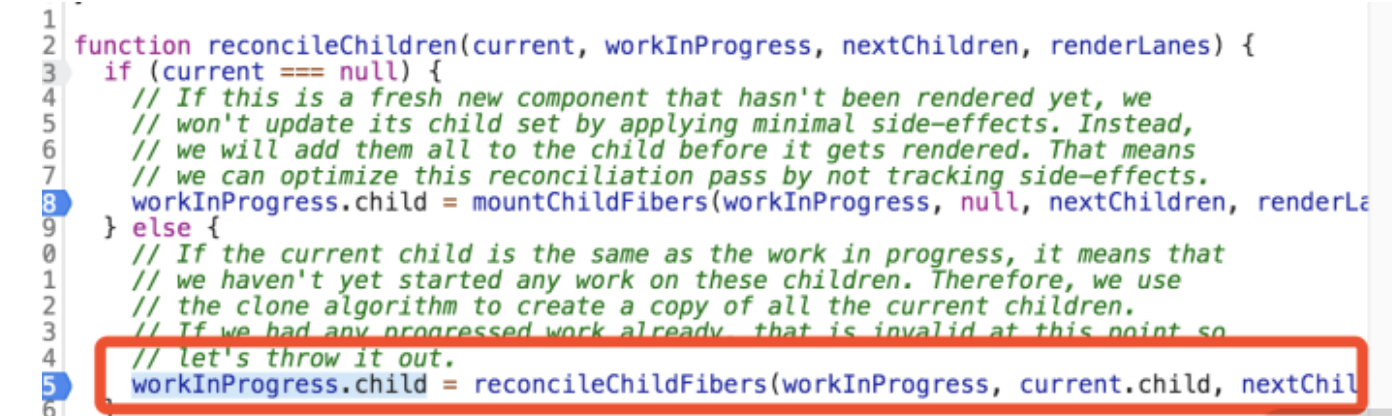
reconcileChildren 函数上下文里的 workInProgress 就是 rootFiber 节点。那么此时,我们就将新创建的 App Fiber 节点和 rootFiber 关联了起来,整个 Fiber 树如下图所示:
# Fiber 节点的创建过程梳理
分析完 App FiberNode 的创建过程,我们先不必急于继续往下走这个渲染链路。因为其实最关键的东西已经讲完了,剩余节点的创建只不过是对 performUnitOfWork、 beginWork 和 ChildReconciler 等相关逻辑的重复。
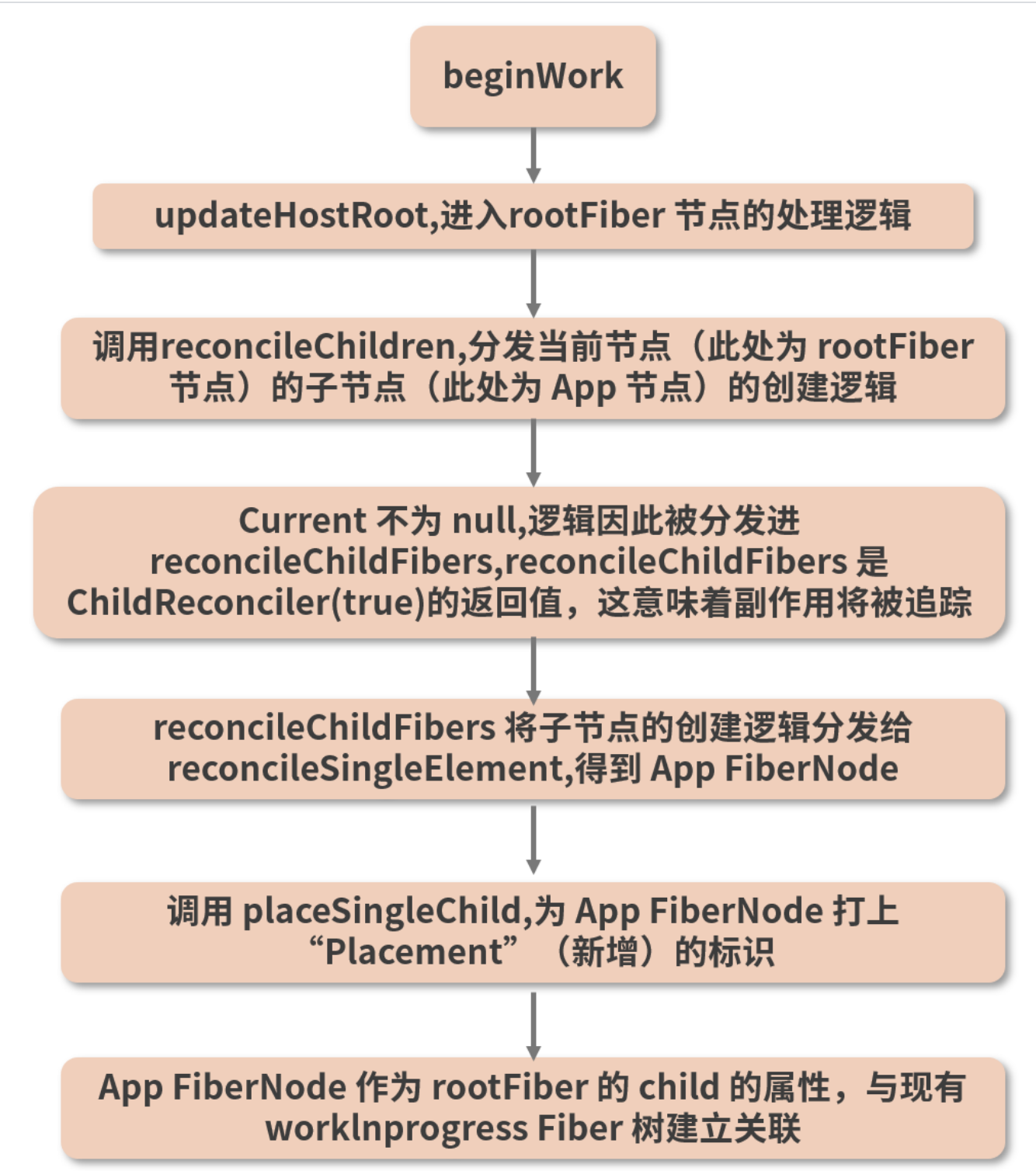
刚刚这一通分析所涉及的调用栈很长,相信不少人如果是初读的话,过程中肯定不可避免地要反复回看,确认自己现在到底在调用栈的哪一环。这里为了方便你把握逻辑脉络,我将本讲讲解的 beginWork 所触发的调用流程总结进一张大图:
# Fiber 树的构建过程
理解了 Fiber 节点的创建过程,就不难理解 Fiber 树的构建过程了。
前面我们已经锲而不舍地研究了各路关键函数的源码逻辑,此时相信你已经能够将函数名与函数的工作内容做到对号入座。这里我们不必再纠结与源码的实现细节,可以直接从工作流程的角度来看后续节点的创建。
# 循环创建新的 Fiber 节点
研究节点创建的工作流,我们的切入点是workLoopSync这个函数。
为什么选它?这里来复习一遍workLoopSync会做什么:
function workLoopSync() {
// 若 workInProgress 不为空
while (workInProgress !== null) {
// 针对它执行 performUnitOfWork 方法
performUnitOfWork(workInProgress);
}
}
它会循环地调用 performUnitOfWork,而 performUnitOfWork,其主要工作是“通过调用 beginWork,来实现新 Fiber 节点的创建”;它还有一个次要工作,就是把新创建的这个 Fiber 节点的值更新到 workInProgress 变量里去。源码中的相关逻辑提取如下:
// 新建 Fiber 节点
next = beginWork$1(current, unitOfWork, subtreeRenderLanes);
// 将新的 Fiber 节点赋值给 workInProgress
if (next === null) {
// If this doesn't spawn new work, complete the current work.
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
如此便能够确保每次 performUnitOfWork 执行完毕后,当前的 workInProgress都存储着下一个需要被处理的节点,从而为下一次的 workLoopSync循环做好准备。
现在我在 workLoopSync 内部打个断点,尝试输出每一次获取到的 workInProgress 的值,workInProgress 值的变化过程如下图所示:

共有 7 个节点,若你点击展开查看每个节点的内容,就会发现这 7 个节点其实分别是:
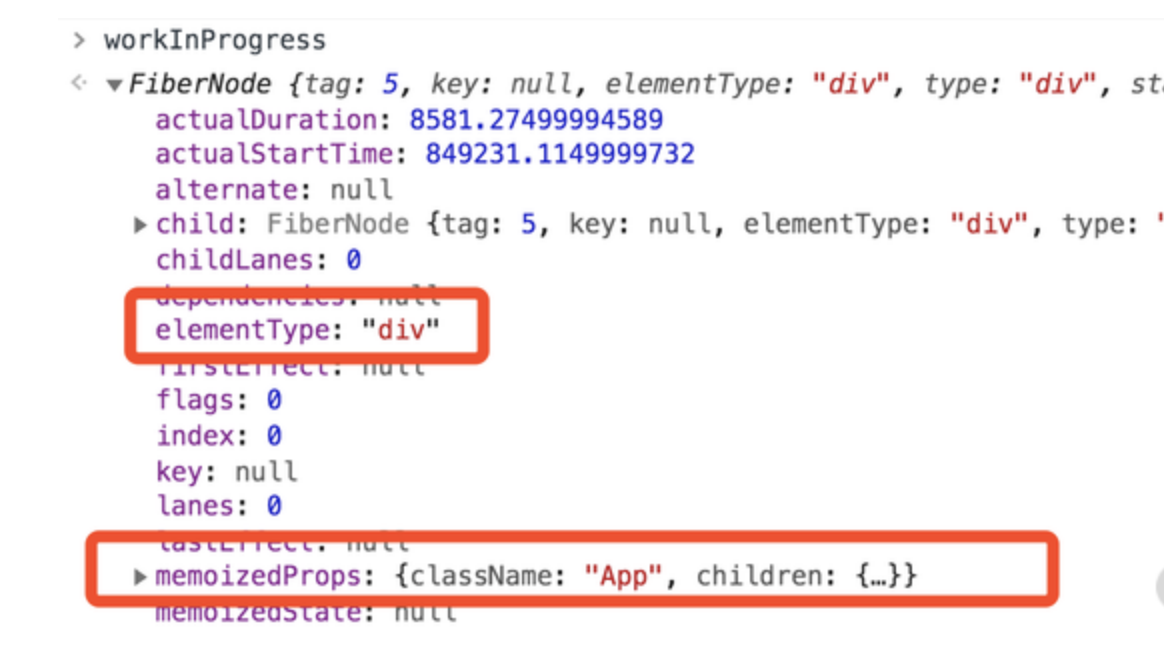
rootFiber(当前 Fiber 树的根节点)App FiberNode(App 函数组件对应的节点)class为 App 的 DOM 元素对应的节点,其内容如下图所示
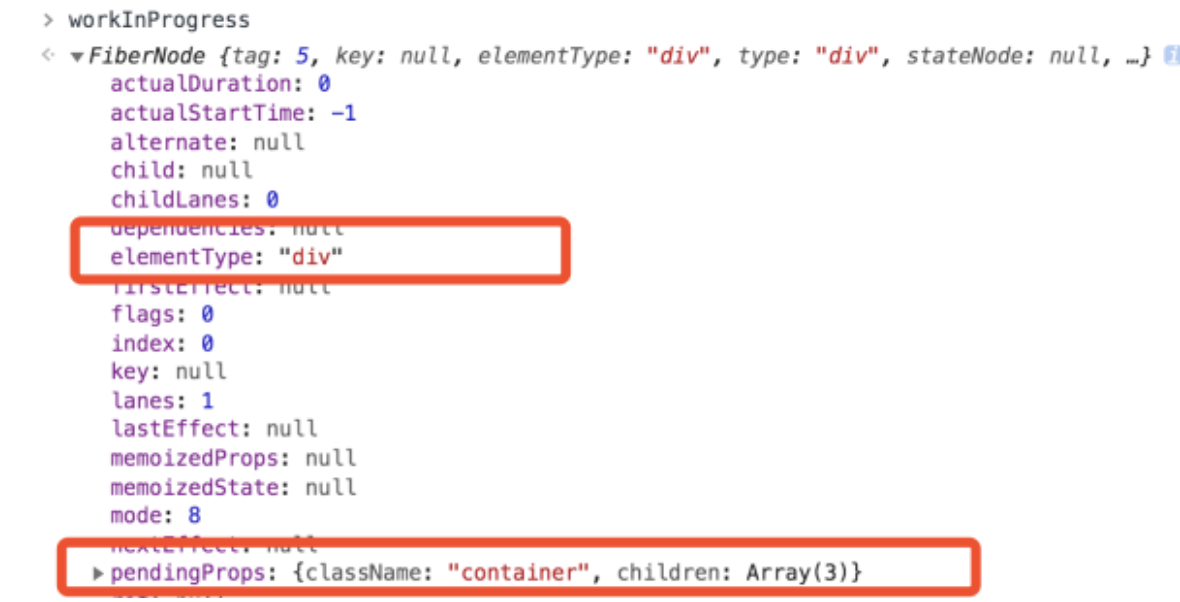
class 为 container 的 DOM 元素对应的节点,其内容如下图所示
h1 标签对应的节点
第 1 个 p 标签对应的 FiberNode,内容为“我是第一段话”,如下图所示
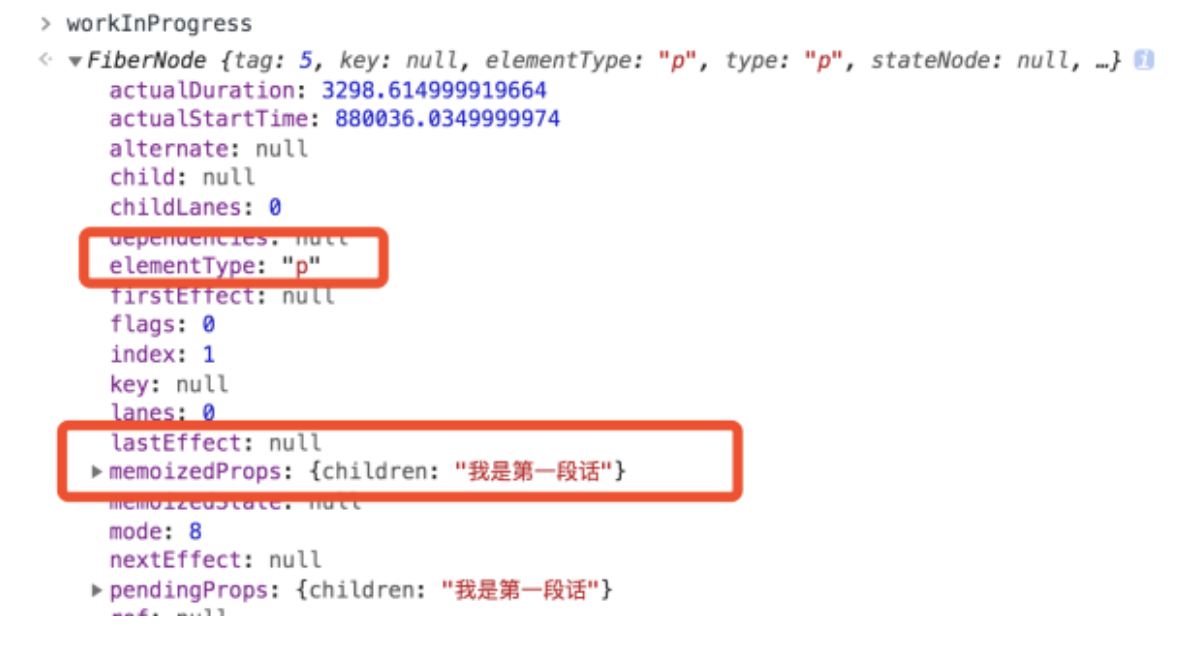
第 2 个 p 标签对应的 FiberNode,内容为“我是第二段话”,如下图所示
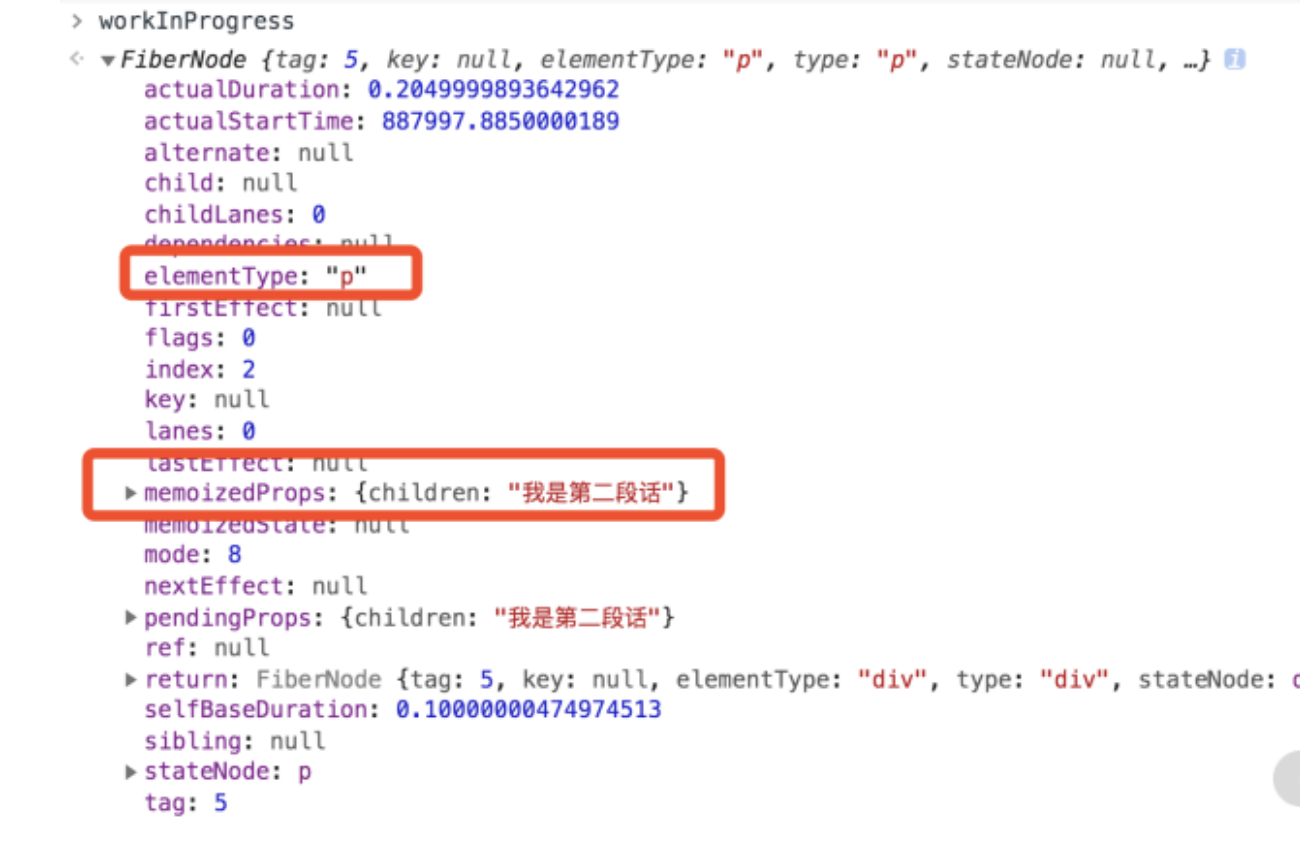
结合这 7 个 FiberNode,再对照对照我们的 Demo:
function App() {
return (
<div className="App">
<div className="container">
<h1>我是标题</h1>
<p>我是第一段话</p>
<p>我是第二段话</p>
</div>
</div>
);
}
你会发现组件自上而下,每一个非文本类型的 ReactElement 都有了它对应的 Fiber 节点。
注: React 并不会为所有的文本类型 ReactElement 创建对应的 FiberNode,这是一种优化策略。是否需要创建 FiberNode,在源码中是通过isDirectTextChild这个变量来区分的
这样一来,我们构建的这棵树里,就多出了不少 FiberNode,如下图所示:
Fiber 节点有是有了,但这些 Fiber 节点之间又是如何相互连接的呢?
# Fiber 节点间是如何连接的呢
不同的 Fiber 节点之间,将通过
child、return、sibling这 3 个属性建立关系,其中child、return记录的是父子节点关系,而sibling记录的则是兄弟节点关系。
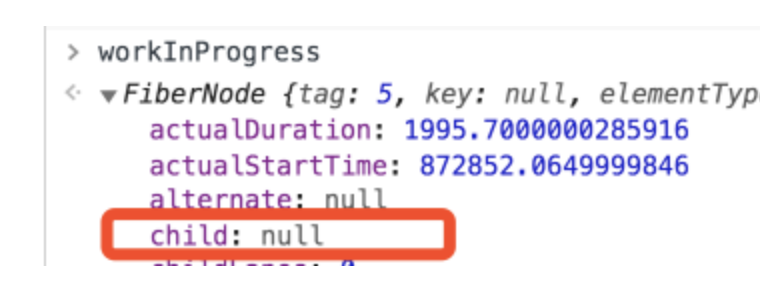
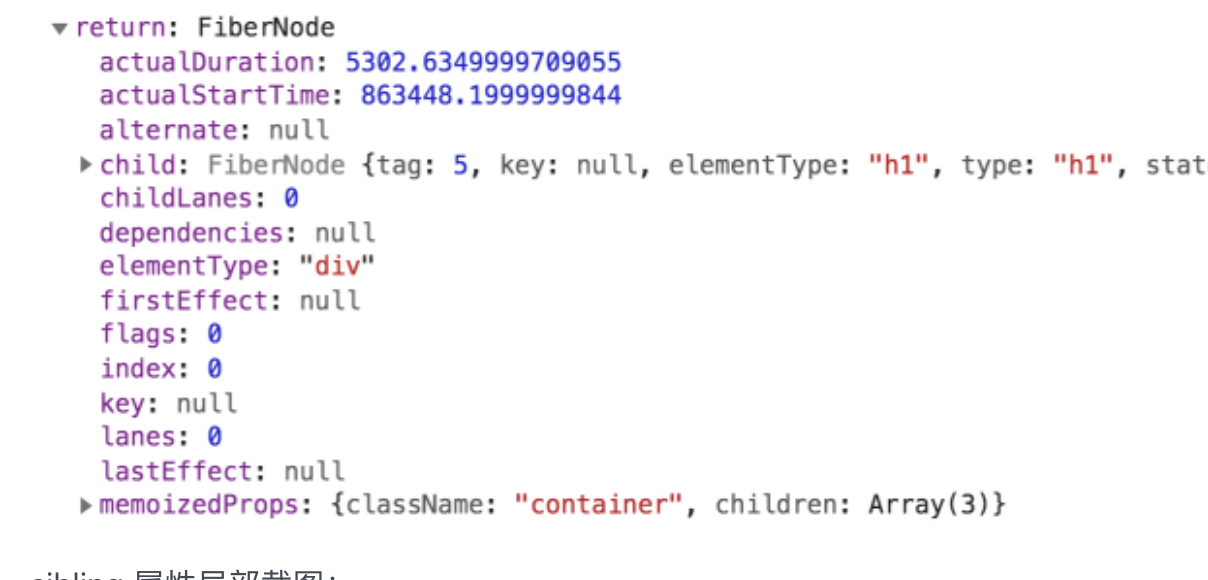
这里我以 h1 这个元素对应的 Fiber 节点为例,给你展示下它是如何与其他节点相连接的。展开这个 Fiber 节点,对它的 child、 return、sibling 3 个属性作截取,如下图所示:
child 属性为 null,说明 h1 节点没有子 Fiber 节点:
return 属性局部截图:
sibling 属性局部截图:

可以看到,
return 属性指向的是 class 为 container 的 div 节点,而sibling 属性指向的是第 1 个 p 节点。结合 JSX 中的嵌套关系我们不难得知 ——FiberNode 实例中,return 指向的是当前 Fiber 节点的父节点,而sibling 指向的是当前节点的第 1 个兄弟节点。
结合这 3 个属性所记录的节点间关系信息,我们可以轻松地将上面梳理出来的新 FiberNode 连接起来:
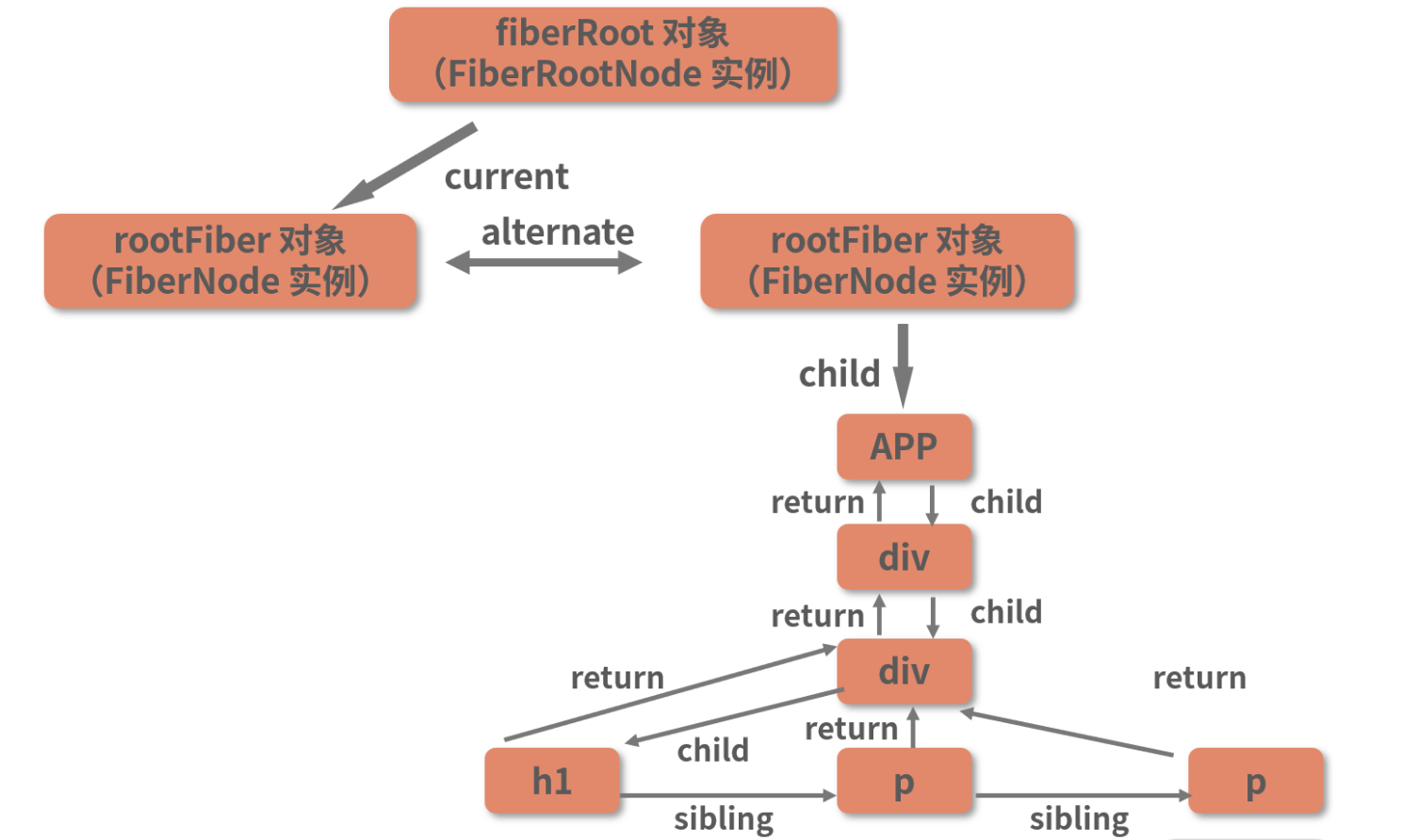
以上便是 workInProgress Fiber 树的最终形态了。从图中可以看出,虽然人们习惯上仍然将眼前的这个产物称为“Fiber 树”,但它的数据结构本质其实已经从树变成了链表。
注意,在分析 Fiber 树的构建过程时,我们选取了 beginWork 作为切入点,但整个 Fiber 树的构建过程中,并不是只有 beginWork 在工作。这其中,还穿插着 completeWork 的工作。只有将 completeWork 和 beginWork 放在一起来看,你才能够真正理解,Fiber 架构下的“深度优先遍历”到底是怎么一回事。
# 四、commit 阶段
实验 Demo 与前面保持一致,代码如下:
import React from "react";
import ReactDOM from "react-dom";
function App() {
return (
<div className="App">
<div className="container">
<h1>我是标题</h1>
<p>我是第一段话</p>
<p>我是第二段话</p>
</div>
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
# completeWork——将 Fiber 节点映射为 DOM 节点
completeWork 的调用时机
首先,我们先在调用栈中定位一下 completeWork。Demo 所对应的调用栈中,第一个 completeWork 出现在下图红框选中的位置:
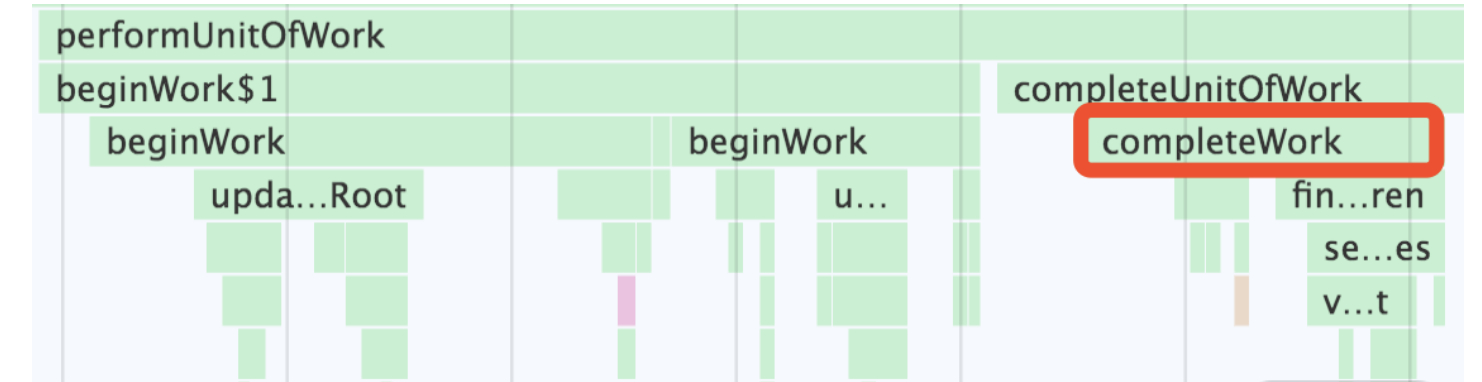
从图上我们需要把握住的一个信息是,从 performUnitOfWork 到 completeWork,中间会经过一个这样的调用链路:
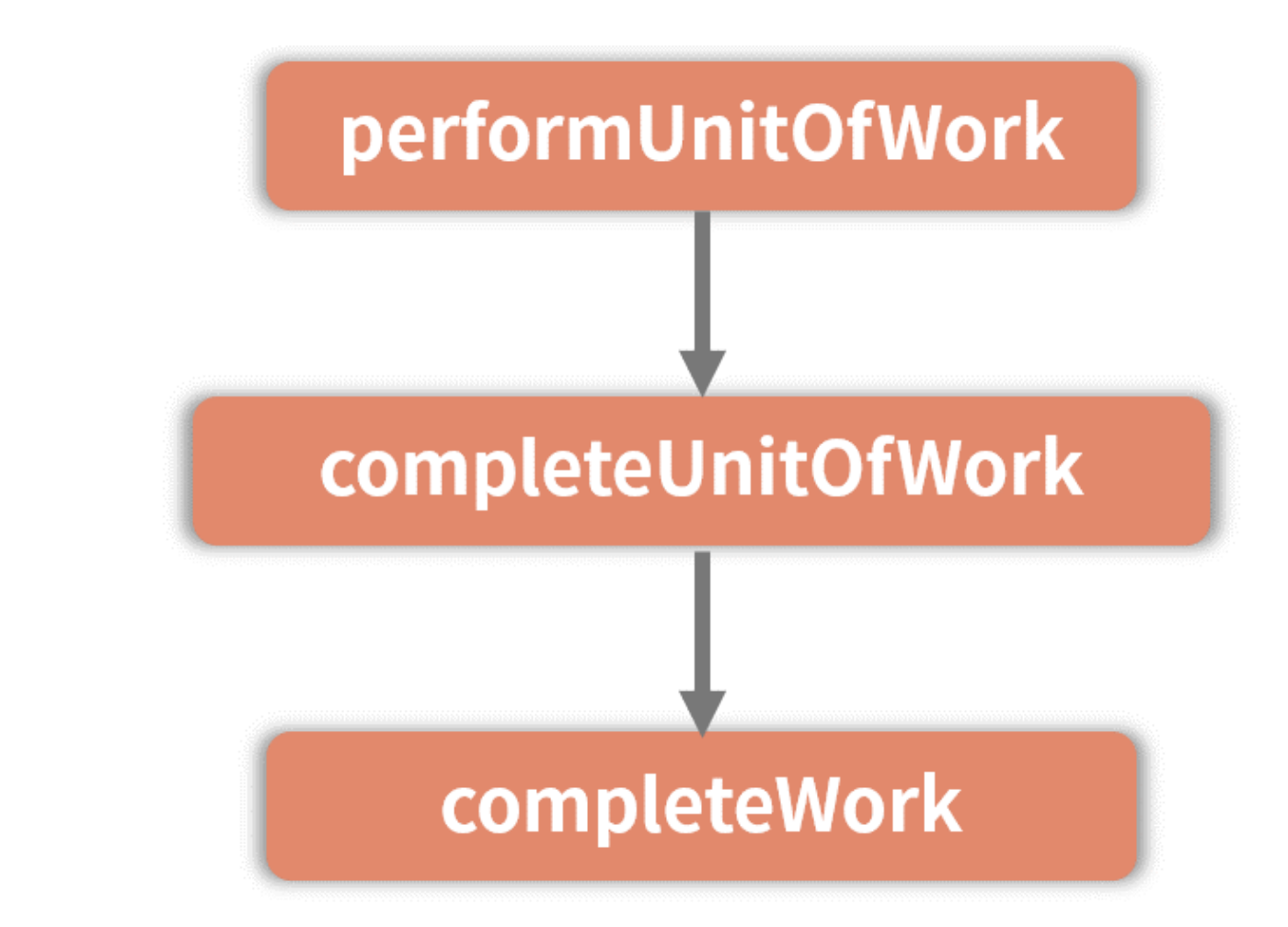
其中 completeUnitOfWork 的工作也非常关键,但眼下我们先拿 completeWork 开刀,你可以暂时将 completeUnitOfWork 简单理解为一个用于发起 completeWork 调用的“工具人”。completeUnitOfWork 是在 performUnitOfWork 中被调用的,那么 performUnitOfWork 是如何把握其调用时机的呢?我们直接来看相关源码(解析在注释里):
function performUnitOfWork(unitOfWork) {
......
// 获取入参节点对应的 current 节点
var current = unitOfWork.alternate;
var next;
if (xxx) {
...
// 创建当前节点的子节点
next = beginWork$1(current, unitOfWork, subtreeRenderLanes);
...
} else {
// 创建当前节点的子节点
next = beginWork$1(current, unitOfWork, subtreeRenderLanes);
}
......
if (next === null) {
// 调用 completeUnitOfWork
completeUnitOfWork(unitOfWork);
} else {
// 将当前节点更新为新创建出的 Fiber 节点
workInProgress = next;
}
......
}
这段源码中你需要提取出的信息是:performUnitOfWork 每次会尝试调用 beginWork 来创建当前节点的子节点,若创建出的子节点为空(也就意味着当前节点不存在子 Fiber 节点),则说明当前节点是一个叶子节点。按照深度优先遍历的原则,当遍历到叶子节点时,“递”阶段就结束了,随之而来的是“归”的过程。因此这种情况下,就会调用 completeUnitOfWork,执行当前节点对应的 completeWork 逻辑。
接下来我们在 Demo 代码的 completeWork 处打上断点,看看第一个走到 completeWork 的节点是哪个,结果如下图所示:
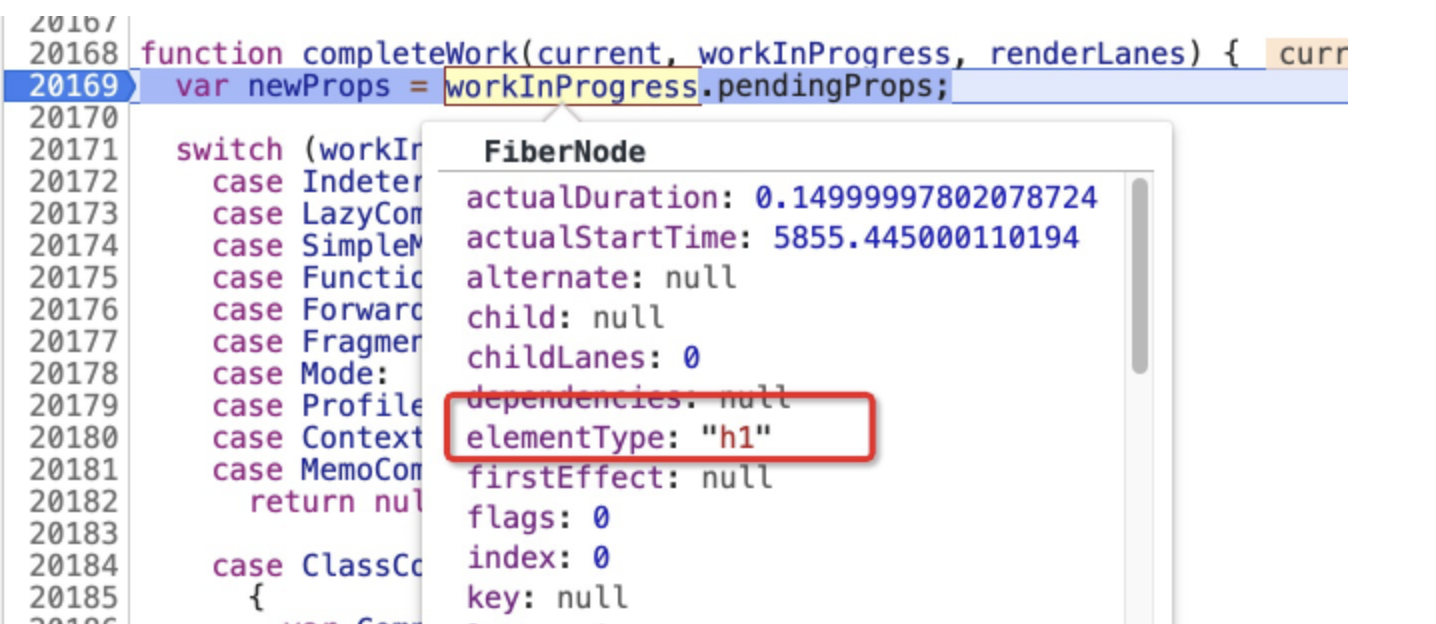
显然,第一个进入 completeWork 的节点是 h1,这也符合我们上一讲所构建出来的 Fiber 树中的节点关系,如下图所示:
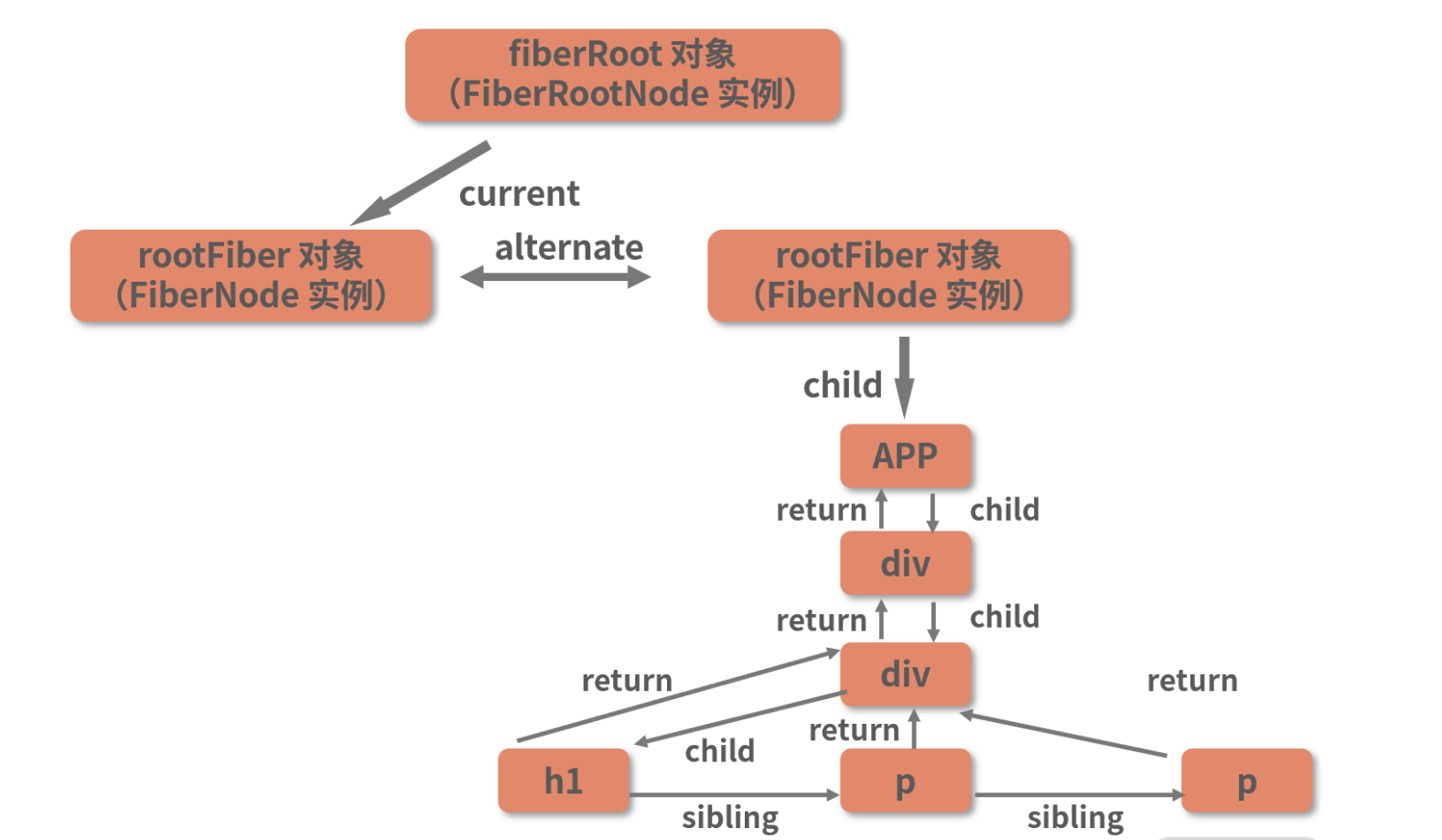
由图可知,按照深度优先遍历的原则,h1 确实将是第一个被遍历到的叶子节点。接下来我们就以 h1 为例,一起看看 completeWork 都围绕它做了哪些事情。
# completeWork 的工作原理
这里仍然为你提取一下 completeWork 的源码结构和主体逻辑,代码如下(解析在注释里):
function completeWork(current, workInProgress, renderLanes) {
// 取出 Fiber 节点的属性值,存储在 newProps 里
var newProps = workInProgress.pendingProps;
// 根据 workInProgress 节点的 tag 属性的不同,决定要进入哪段逻辑
switch (workInProgress.tag) {
case ......:
return null;
case ClassComponent:
{
.....
}
case HostRoot:
{
......
}
// h1 节点的类型属于 HostComponent,因此这里为你讲解的是这段逻辑
case HostComponent:
{
popHostContext(workInProgress);
var rootContainerInstance = getRootHostContainer();
var type = workInProgress.type;
// 判断 current 节点是否存在,因为目前是挂载阶段,因此 current 节点是不存在的
if (current !== null && workInProgress.stateNode != null) {
updateHostComponent$1(current, workInProgress, type, newProps, rootContainerInstance);
if (current.ref !== workInProgress.ref) {
markRef$1(workInProgress);
}
} else {
// 这里首先是针对异常情况进行 return 处理
if (!newProps) {
if (!(workInProgress.stateNode !== null)) {
{
throw Error("We must have new props for new mounts. This error is likely caused by a bug in React. Please file an issue.");
}
}
return null;
}
// 接下来就为 DOM 节点的创建做准备了
var currentHostContext = getHostContext();
// _wasHydrated 是一个与服务端渲染有关的值,这里不用关注
var _wasHydrated = popHydrationState(workInProgress);
// 判断是否是服务端渲染
if (_wasHydrated) {
// 这里不用关注,请你关注 else 里面的逻辑
if (prepareToHydrateHostInstance(workInProgress, rootContainerInstance, currentHostContext)) {
markUpdate(workInProgress);
}
} else {
// 这一步很关键, createInstance 的作用是创建 DOM 节点
var instance = createInstance(type, newProps, rootContainerInstance, currentHostContext, workInProgress);
// appendAllChildren 会尝试把上一步创建好的 DOM 节点挂载到 DOM 树上去
appendAllChildren(instance, workInProgress, false, false);
// stateNode 用于存储当前 Fiber 节点对应的 DOM 节点
workInProgress.stateNode = instance;
// finalizeInitialChildren 用来为 DOM 节点设置属性
if (finalizeInitialChildren(instance, type, newProps, rootContainerInstance)) {
markUpdate(workInProgress);
}
}
......
}
return null;
}
case HostText:
{
......
}
case SuspenseComponent:
{
......
}
case HostPortal:
......
return null;
case ContextProvider:
......
return null;
......
}
{
{
throw Error("Unknown unit of work tag (" + workInProgress.tag + "). This error is likely caused by a bug in React. Please file an issue.");
}
}
}
试图捋顺这段 completeWork 逻辑,你需要掌握以下几个要点。
completeWork的核心逻辑是一段体量巨大的switch语句,在这段switch语句中,completeWork将根据workInProgress节点的tag属性的不同,进入不同的DOM节点的创建、处理逻辑。- 在 Demo 示例中,h1 节点的 tag 属性对应的类型应该是 HostComponent,也就是“原生 DOM 元素类型”。
completeWork中的current、 workInProgress分别对应的是下图中左右两棵Fiber树上的节点:
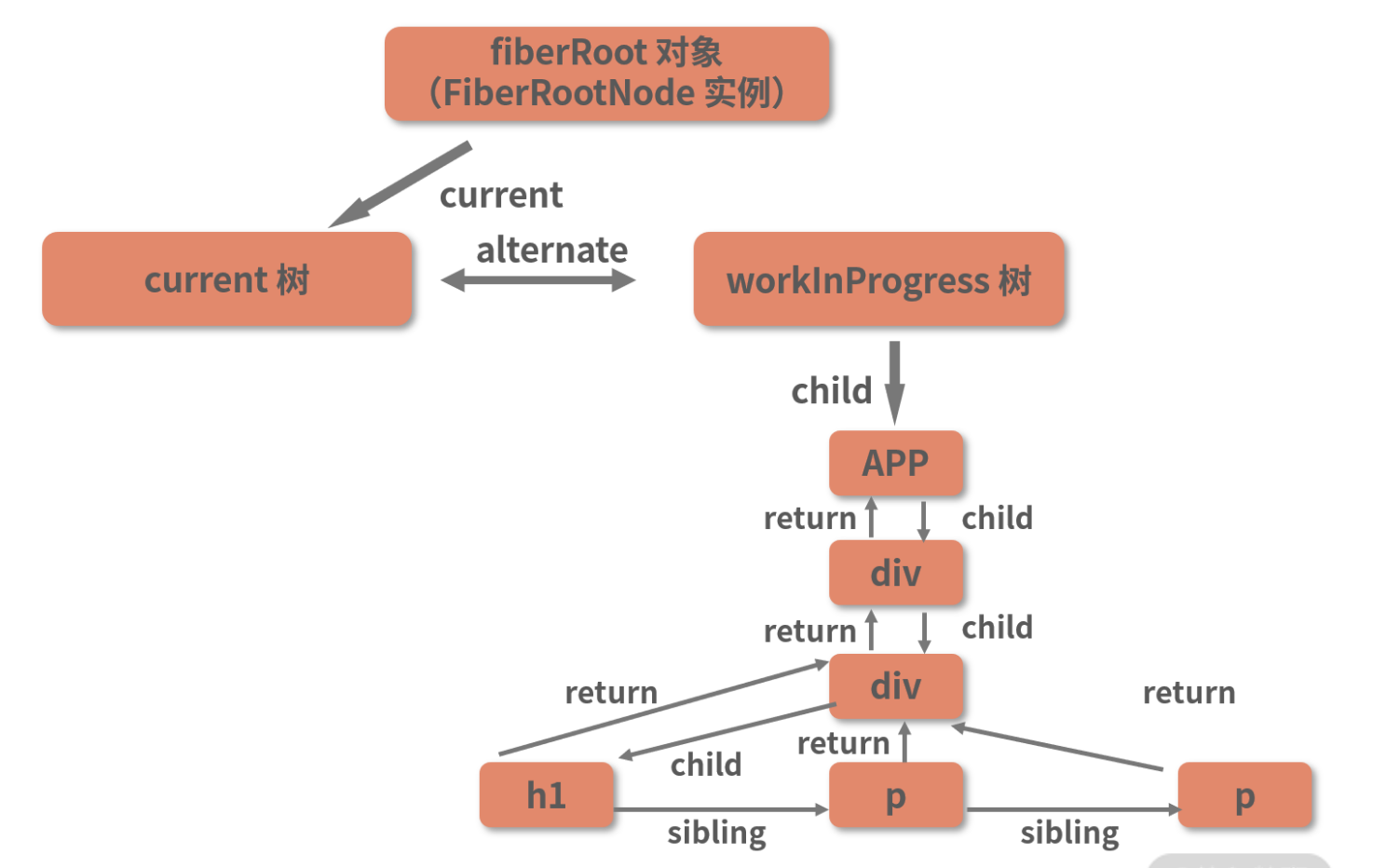
其中 workInProgress 树代表的是“当前正在 render 中的树”,而 current 树则代表“已经存在的树”。
workInProgress 节点和 current 节点之间用 alternate 属性相互连接。在组件的挂载阶段,current 树只有一个 rootFiber 节点,并没有其他内容。因此 h1 这个 workInProgress 节点对应的 current 节点是 null。
带着上面这些前提,再去结合注释读一遍上面提炼出来的源码,思路是不是就清晰多了?
捋顺思路后,我们直接来提取知识点。关于 completeWork,你需要明白以下几件事。
- 用一句话来总结
completeWork的工作内容:负责处理 Fiber 节点到 DOM 节点的映射逻辑。 completeWork内部有 3 个关键动作:- 创建
DOM节点(CreateInstance) - 将 DOM 节点插入到 DOM 树中(AppendAllChildren)
- 为 DOM 节点设置属性(FinalizeInitialChildren)
- 创建
- 创建好的 DOM 节点会被赋值给 workInProgress 节点的 stateNode 属性。也就是说当我们想要定位一个 Fiber 对应的 DOM 节点时,访问它的 stateNode 属性就可以了。这里我们可以尝试访问运行时的 h1 节点的 stateNode 属性,结果如下图所示:
![]()
- 将 DOM 节点插入到 DOM 树的操作是通过
appendAllChildren函数来完成的

说是将 DOM 节点插入到 DOM 树里去,实际上是将子 Fiber 节点所对应的 DOM 节点挂载到其父 Fiber 节点所对应的 DOM 节点里去。比如说在本讲 Demo 所构建出的 Fiber 树中,h1 节点的父结点是 div,那么 h1 对应的 DOM 节点就理应被挂载到 div 对应的 DOM 节点里去。
那么如果执行 appendAllChildren 时,父级的 DOM 节点还不存在怎么办?
比如 h1 节点作为第一个进入 completeWork 的节点,它的父节点 div 对应的 DOM 就尚不存在。其实不存在也没关系,反正 h1 DOM 节点被创建后,会作为 h1 Fiber 节点的 stateNode 属性存在,丢不掉的。当父节点 div 进入 appendAllChildren 逻辑后,会逐个向下查找并添加自己的后代节点,这时候,h1 就会被它的父级 DOM 节点“收入囊中”啦~
# completeUnitOfWork —— 开启收集 EffectList 的“大循环”
completeUnitOfWork 的作用是开启一个大循环,在这个大循环中,将会重复地做下面三件事:
- 针对传入的当前节点,调用 completeWork,completeWork 的工作内容前面已经讲过,这一步应该是没有异议的;
- 将当前节点的副作用链(EffectList)插入到其父节点对应的副作用链(EffectList)中;
- 以当前节点为起点,循环遍历其兄弟节点及其父节点。当遍历到兄弟节点时,将 return 掉当前调用,触发兄弟节点对应的 performUnitOfWork 逻辑;而遍历到父节点时,则会直接进入下一轮循环,也就是重复 1、2 的逻辑。
步骤 1 无须多言,接下来我将为你解读步骤 2 和步骤 3 的含义。
# completeUnitOfWork 开启下一轮循环的原则
在理解副作用链之前,首先要理解 completeUnitOfWork 开启下一轮循环的原则,也就是步骤 3。步骤 3 相关的源码如下所示(解析在注释里):
do {
......
// 这里省略步骤 1 和步骤 2 的逻辑
// 获取当前节点的兄弟节点
var siblingFiber = completedWork.sibling;
// 若兄弟节点存在
if (siblingFiber !== null) {
// 将 workInProgress 赋值为当前节点的兄弟节点
workInProgress = siblingFiber;
// 将正在进行的 completeUnitOfWork 逻辑 return 掉
return;
}
// 若兄弟节点不存在,completeWork 会被赋值为 returnFiber,也就是当前节点的父节点
completedWork = returnFiber;
// 这一步与上一步是相辅相成的,上下文中要求 workInProgress 与 completedWork 保持一致
workInProgress = completedWork;
} while (completedWork !== null);
步骤 3 是整个循环体的收尾工作,它会在当前节点相关的各种工作都做完之后执行。
当前节点处理完了,自然是去寻找下一个可以处理的节点。我们知道,当前的 Fiber 节点之所以会进入 completeWork,是因为“递无可递”了,才会进入“归”的逻辑,这就意味着当前 Fiber 要么没有 child 节点、要么 child 节点的 completeWork 早就执行过了。因此 child 节点不会是下次循环需要考虑的对象,下次循环只需要考虑兄弟节点(siblingFiber)和父节点(returnFiber)。
那么为什么在源码中,遇到兄弟节点会 return,遇到父节点才会进入下次循环呢?这里我以 h1 节点的节点关系为例进行说明。请看下图:
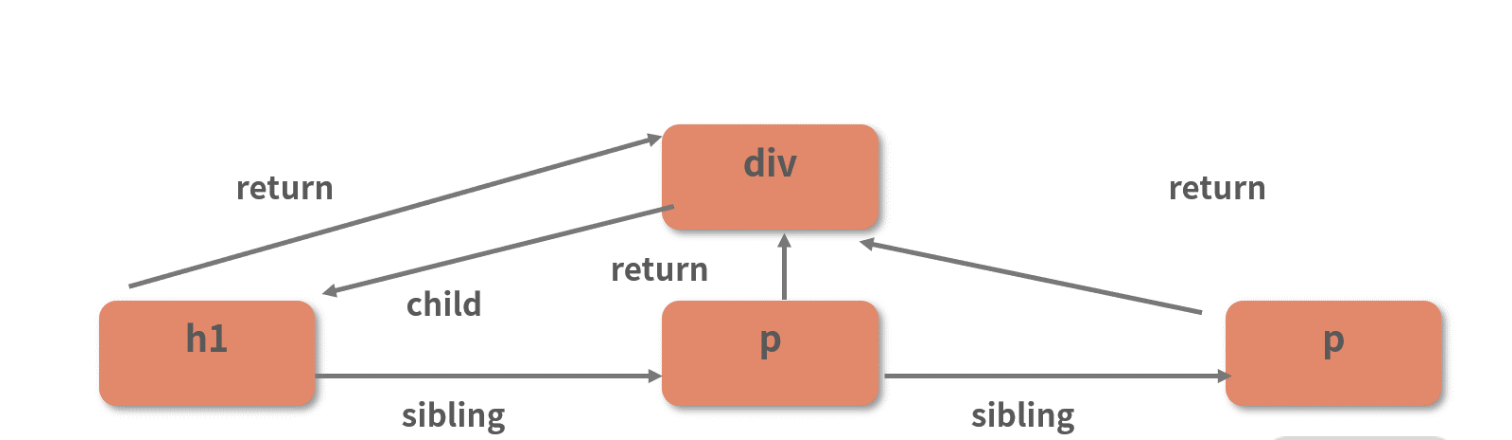
结合前面的分析和图示可知,h1 节点是递归过程中所触及的第一个叶子节点,也是其兄弟节点中被遍历到的第一个节点;而剩下的两个 p 节点,此时都还没有被遍历到,也就是说连 beginWork 都没有执行过。
因此对于 h1 节点的兄弟节点来说,当下的第一要务是回去从 beginWork 开始走起,直到 beginWork “递无可递”时,才能够执行 completeWork 的逻辑。beginWork 的调用是在 performUnitOfWork 里发生的,因此 completeUnitOfWork 一旦识别到当前节点的兄弟节点不为空,就会终止后续的逻辑,退回到上一层的 performUnitOfWork 里去。
接下来我们再来看 h1 的父节点 div:在向下递归到 h1 的过程中,div 必定已经被遍历过了,也就是说 div 的“递”阶段( beginWork) 已经执行完毕,只剩下“归”阶段的工作要处理了。因此,对于父节点,completeUnitOfWork 会毫不犹豫地把它推到下一次循环里去,让它进入 completeWork 的逻辑。
值得注意的是,completeUnitOfWork 中处理兄弟节点和父节点的顺序是:先检查兄弟节点是否存在,若存在则优先处理兄弟节点;确认没有待处理的兄弟节点后,才转而处理父节点。这也就意味着,completeWork 的执行是严格自底向上的,子节点的 completeWork 总会先于父节点执行。
# 副作用链(effectList)的设计与实现
无论是 beginWork 还是 completeWork,它们的应用对象都是 workInProgress 树上的节点。我们说 render 阶段是一个递归的过程,“递归”的对象,正是这棵 workInProgress 树(见下图右侧高亮部分):
那么我们递归的目的是什么呢?或者说,render 阶段的工作目标是什么呢?
# render 阶段的工作目标是找出界面中需要处理的更新
在实际的操作中,并不是所有的节点上都会产生需要处理的更新。比如在挂载阶段,对图中的整棵 workInProgress 递归完毕后,React 会发现实际只需要对 App 节点执行一个挂载操作就可以了;而在更新阶段,这种现象更为明显。
更新阶段与挂载阶段的主要区别在于更新阶段的 current 树不为空,比如说情况可以是下图这样子的:
假如说我的某一次操作,仅仅对 p 节点产生了影响,那么对于渲染器来说,它理应只关注 p 节点这一处的更新。这时候问题就来了:怎样做才能让渲染器又快又好地定位到那些真正需要更新的节点呢?
在 render 阶段,我们通过艰难的递归过程来明确“p 节点这里有一处更新”这件事情。按照 React 的设计思路,render 阶段结束后,“找不同”这件事情其实也就告一段落了。commit 只负责实现更新,而不负责寻找更新,这就意味着我们必须找到一个办法能让 commit 阶段“坐享其成”,能直接拿到 render 阶段的工作成果。而这,正是副作用链(effectList)的价值所在。
副作用链(effectList) 可以理解为 render 阶段“工作成果”的一个集合:每个 Fiber 节点都维护着一个属于它自己的 effectList,effectList 在数据结构上以链表的形式存在,链表内的每一个元素都是一个 Fiber 节点。这些 Fiber 节点需要满足两个共性:
- 都是当前 Fiber 节点的后代节点
- 都有待处理的副作用
没错,Fiber 节点的 effectList 里记录的并非它自身的更新,而是其需要更新的后代节点。带着这个结论,我们再来品品小节开头 completeUnitOfWork 中的“步骤 2”:
将当前节点的副作用链(effectList)插入到其父节点对应的副作用链(effectList)中。
咱们前面已经分析过,“completeWork 是自底向上执行的”,也就是说,子节点的 completeWork 总是比父节点先执行。试想,若每次处理到一个节点,都将当前节点的 effectList 插入到其父节点的 effectList 中。那么当所有节点的 completeWork 都执行完毕时,我是不是就可以从“终极父节点”,也就是 rootFiber 上,拿到一个存储了当前 Fiber 树所有 effect Fiber的“终极版”的 effectList 了?
把所有需要更新的 Fiber 节点单独串成一串链表,方便后续有针对性地对它们进行更新,这就是所谓的“收集副作用”的过程。
这里我以挂载过程为例,带你分析一下这个过程是如何实现的。
首先我们要知道的是,这个 effectList 链表在 Fiber 节点中是通过 firstEffect 和 lastEffect 来维护的,如下图所示:
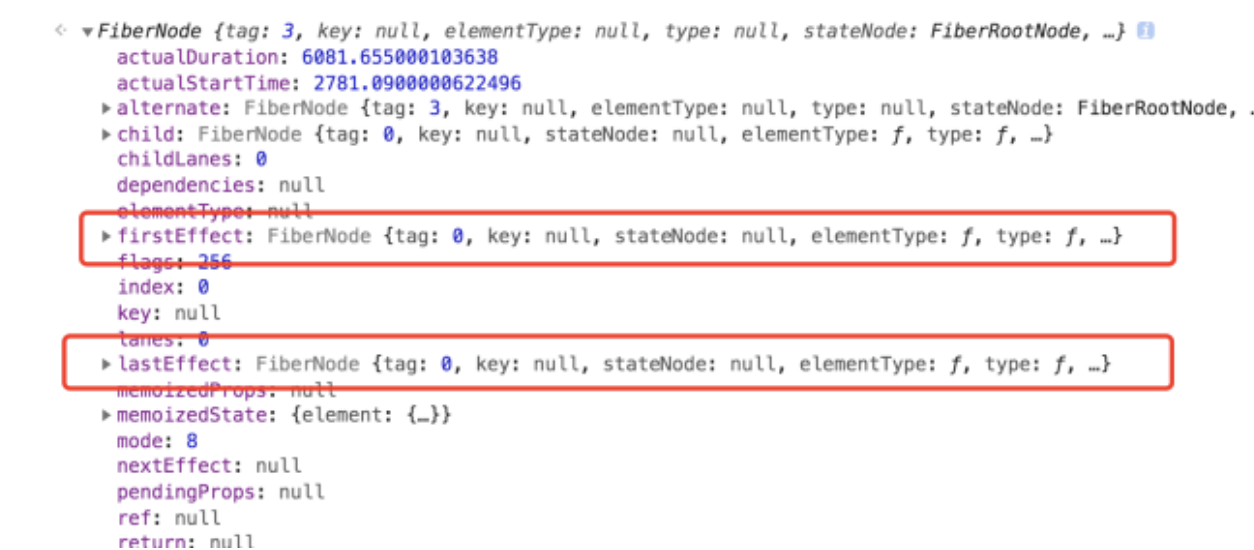
其中 firstEffect 表示 effectList 的第一个节点,而 lastEffect 则记录最后一个节点。
对于挂载过程来说,我们唯一要做的就是把 App 组件挂载到界面上去,因此 App 后代节点们的 effectList 其实都是不存在的。effectList 只有在 App 的父节点(rootFiber)这才不为空。
那么 effectList 的创建逻辑又是怎样的呢?其实非常简单,只需要为 firstEffect 和 lastEffect 各赋值一个引用即可。以下是从 completeUnitOfWork 源码中提取出的相关逻辑(解析在注释里):
// 若副作用类型的值大于“PerformedWork”,则说明这里存在一个需要记录的副作用
if (flags > PerformedWork) {
// returnFiber 是当前节点的父节点
if (returnFiber.lastEffect !== null) {
// 若父节点的 effectList 不为空,则将当前节点追加到 effectList 的末尾去
returnFiber.lastEffect.nextEffect = completedWork;
} else {
// 若父节点的 effectList 为空,则当前节点就是 effectList 的 firstEffect
returnFiber.firstEffect = completedWork;
}
// 将 effectList 的 lastEffect 指针后移一位
returnFiber.lastEffect = completedWork;
}
代码中的 flags 咱们已经反复强调过了,它旧时的名字叫“effectTag”,是用来标识副作用类型的;而“completedWork”这个变量,在当前上下文中存储的就是“正在被执行 completeWork 相关逻辑”的节点;至于“PerformedWork”,它是一个值为 1 的常量,React 规定若 flags(又名 effectTag)的值小于等于 1,则不必提交到 commit 阶段。因此 completeUnitOfWork 只会对 flags 大于 PerformedWork 的 effect fiber 进行收集。
结合这些信息,再去读一遍源码片段,相信你的理解过程就会很流畅了。这里我以 App 节点为例,带你走一遍 effectList 的创建过程:
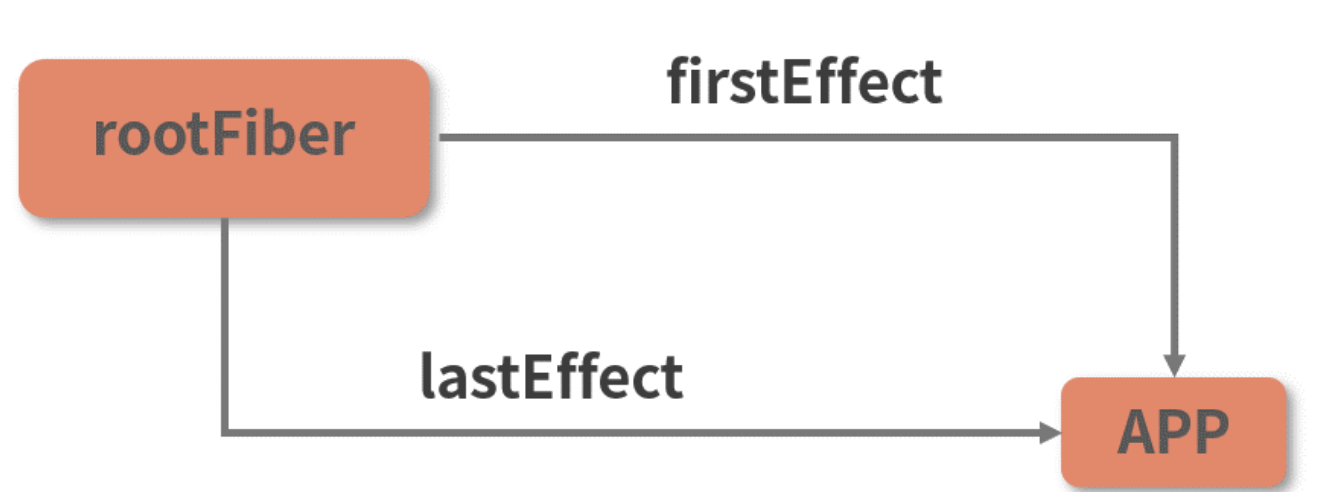
- App FiberNode 的 flags 属性为 3,大于 PerformedWork,因此会进入 effectList 的创建逻辑;
- 创建 effectList 时,并不是为当前 Fiber 节点创建,而是为它的父节点创建,App 节点的父节点是 rootFiber,rootFiber 的 effectList 此时为空;
- rootFiber 的 firstEffect 和 lastEffect 指针都会指向 App 节点,App 节点由此成为 effectList 中的唯一一个 FiberNode,如下图所示。
OK,读到这里,相信你已经对 effectList 的创建过程知根知底了。
现在,即便你对部分源码细节的消化可能没有那么快,也请你不要因为这些细节去中断自己串联整个渲染链路的思路。你只需要把握住“根节点(rootFiber)上的 effectList 信息,是 commit 阶段的更新线索”这个结论,就足以将 render 阶段和 commit 阶段串联起来。
# commit 阶段工作流简析
在整个 ReactDOM.render 的渲染链路中,render 阶段是 Fiber 架构的核心体现,也是我们讲解的重点。对于 render 阶段,我对你的期望是“熟悉”,为了达成这个目标,我们对 render 阶段的学习还会再持续一个课时;而对于 commit 阶段,我只要求你做到“了解”。因此这里我会快速地带你过一遍 commit 阶段的重点知识,不占用你太多时间。
commit 会在 performSyncWorkOnRoot 中被调用,如下图所示:
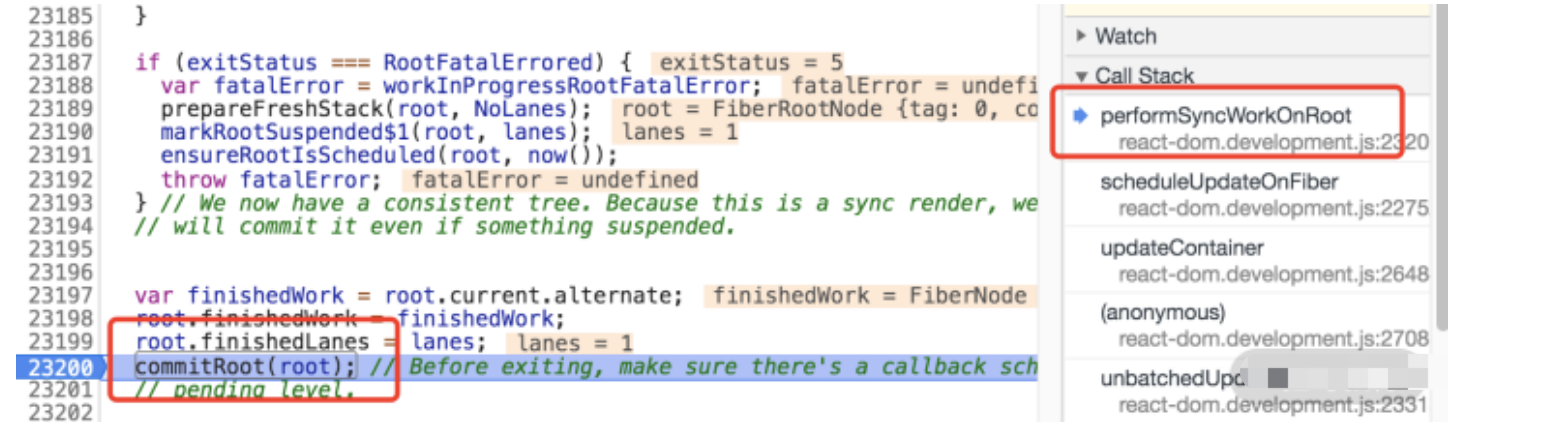
这里的入参 root 并不是 rootFiber,而是 fiberRoot(FiberRootNode)实例。fiberRoot 的 current 节点指向 rootFiber,因此拿到 effectList 对后续的 commit 流程来说不是什么难事。
从流程上来说,commit 共分为 3 个阶段:before mutation、mutation、layout。
- before mutation 阶段,这个阶段 DOM 节点还没有被渲染到界面上去,过程中会触发 getSnapshotBeforeUpdate,也会处理 useEffect 钩子相关的调度逻辑。
- mutation,这个阶段负责 DOM 节点的渲染。在渲染过程中,会遍历 effectList,根据 flags(effectTag)的不同,执行不同的 DOM 操作。
- layout,这个阶段处理 DOM 渲染完毕之后的收尾逻辑。比如调用 componentDidMount/componentDidUpdate,调用 useLayoutEffect 钩子函数的回调等。除了这些之外,它还会把 fiberRoot 的 current 指针指向 workInProgress Fiber 树。
关于 commit 阶段的实现细节,感兴趣的同学课下可以参阅 commit 相关源码 (opens new window),这里不再展开讨论。对于 commit,如果你只能记住一个知识点,我希望你记住
它是一个绝对同步的过程。render 阶段可以同步也可以异步,但 commit 一定是同步的。